【Exploit trick】针对cred结构的cross-cache利用(corCTF 2022-cache-of-castaways)
保护机制:SMAP, SMEP, KPTI, KASLR 及常用的保护机制,内核版本是 5.18.3 所以禁用了 msg_msg。
源码文件下载:https://github.com/bsauce/CTF/tree/master/corCTF%202022-cache-of-castaways
漏洞分析:特殊cache(漏洞对象大小为512字节)中的6字节堆溢出,可以分配 50*8 个漏洞对象。
利用总结:构造 cross-cache 溢出,利用漏洞对象篡改相邻的 cred 对象。
- (1)喷射cred对象
- (1-1)先创建100个子进程,耗尽
cred_jarcache; - (1-2)采用
setsockopt()喷射1000个大小为4096的ring buffer,释放500个下标为奇数的ring buffer; - (1-3)创建320个子进程,以喷射320个
cred对象(注意,调用__NR_clone时采用汇编代码调用,加上标志位CLONE_FILES | CLONE_FS | CLONE_VM | CLONE_SIGHAND,这样进行进程拷贝时能避免许多内存分配的噪声),子进程负责检查是否为root权限,是则执行execve("/bin/sh", args, 0);
- (1-1)先创建100个子进程,耗尽
- (2)喷射漏洞对象并触发堆溢出
- (2-1)释放500个下标为偶数的
ring buffer; - (2-2)喷射
30*8个漏洞对象,尝试溢出篡改cred(注意cred->usage伪造为1); - (2-3)利用pipe通知
(1-3)中的320个子进程开始检查是否获得root权限。
- (2-1)释放500个下标为偶数的
1. 漏洞分析
源码参见 castaway.c。
程序功能:包含两个ioctl命令,一是添加chunk(对象大小是512字节,最多添加400个chunk);二是编辑chunk,有6字节溢出。
static long castaway_edit(int64_t idx, uint64_t size, char *buf)
{
char temp[CHUNK_SIZE];
if (idx < 0 || idx >= MAX || !castaway_arr[idx])
{
goto edit_fail;
}
if (size > CHUNK_SIZE || copy_from_user(temp, buf, size))
{
goto edit_fail;
}
memcpy(castaway_arr[idx]->buf, temp, size); // 漏洞点: 堆块只有 512 字节,但是从偏移 0x6 开始拷贝,最多可以拷贝 512 字节,导致溢出
return size;
edit_fail:
printk(KERN_INFO "castaway chunk editing failed\n");
return -1;
}
难点:
- (1)漏洞对象位于一个隔绝的cache(采用
SLAB_PANIC | SLAB_ACCOUNTflag 分配),由于作者编译的内核设置了CONFIG_MEMCG_KMEM,所以这个cache会被隔绝(参见 duasynt documents); - (2)作者还禁用了
CONFIG_SLAB_MERGE_DEFAULT,避免find_mergeable函数将拥有相似属性的cache整合。 - (3)不仅有 freelist randomization 和 hardening 保护机制,内核还将 freelist 指针放在堆块中间,且漏洞对象不含函数指针等任何指针,如何利用呢?
2. 漏洞利用
2-1. cross-cache介绍
cross-cache:利用方法就是 cross cache overflow,这种方法没有在CTF中出现过,但是在真实CVE中出现很多次了,例如,CVE-2022-27666,CVE-2022-0185,CVE-2022-29582,还有对该技术的讨论,AUTOSLAB , kmalloc internals。总结来说,kmalloc slab allocation 是基于 buddy allocator 的,当kmalloc cache 上没有足够的 chunk 时,会向 buddy allocator 申请 order-n page,具体会调用 new_slab() -> allocate_slab() -> alloc_slab_page() 向 buddy allocator 申请页。
/*
* Slab allocation and freeing
*/
static inline struct slab *alloc_slab_page(gfp_t flags, int node,
struct kmem_cache_order_objects oo)
{
struct folio *folio;
struct slab *slab;
unsigned int order = oo_order(oo); // order = kmem_cache->oo.x >> 16
if (node == NUMA_NO_NODE)
folio = (struct folio *)alloc_pages(flags, order);
else
folio = (struct folio *)__alloc_pages_node(node, flags, order);
if (!folio)
return NULL;
slab = folio_slab(folio);
__folio_set_slab(folio);
if (page_is_pfmemalloc(folio_page(folio, 0)))
slab_set_pfmemalloc(slab);
return slab;
}
页分配器原理:
buddy allocator 为每个 order-n page 保存着一个 FIFO queue 数组,order-n page 表示 $2^n$ 个连续页的内存。当你释放chunk后导致slab全部空闲时,slab allocator 就会将页还给 buddy allocator。
slab对应的order由很多因素决定,如 slab chunk 大小、系统定义、内核编译等,最简单的方法是查看
/proc/slabinfo,本题中,被隔绝的 512 字节对象需要 order-0 page。如果所申请的 order-n page 队列为空,则将 order-n+1 的页一分为二,一半返回给申请者,一半保存在 order-n 中;如果1个page返回给 buddy allocator,且其对应的 buddy page 也在同一队列中,则整合后放在下一order的page队列中。
可行性:以往的 cross cache overflow exp 中,基本都是从没有可用对象的 slab 溢出到有可用对象的 slab,这种 cross cache 策略也适用于UAF漏洞,很多exp要求目标对象位于大于 order-0 的page,以减少噪声、提高稳定性(因为很多内核对象都位于 order-0 的page),但并不表示 order-0 page 上的 cross-cache overflow 不可行(只要噪声足够低)。如果 order-0 可用,就可以解锁许多可用的对象,例如 cred 对象(位于 cred_jar cache 上)。
2-2. 利用方法与页喷射
利用方法:这个方法的优点是,不需要绕过KASLR、任意写、ROP chain,是纯粹基于数据流的利用方法。
- 先耗尽
cred_jar,使下次分配从 order-0 page 取内存; - 耗尽高order的page,都转为 order-0 page;
- 释放部分page,避免 page merging,堆喷cred对象;
- 释放剩余page,最后堆喷漏洞对象来溢出覆写至少1个cred对象。
喷射cred:采用fork的方法,fork可以减少噪声。
页喷方法:驱动只能分配最多400个 512字节的对象,占据约50个page(每个slab有8个chunk),没有释放选项,所以需要构造一个更好的页喷射原语。首先找到所有页分配函数的引用点,如 __get_free_pages() / alloc_page() / alloc_pages()。D3v17提出采用 CVE-2017-7308 的页分配方案,如果使用 setsockopt 将 packet 版本设置为 TPACKET_V1/TPACKET_V2 ,然后使用同一syscall来初始化 PACKET_TX_RING(使用 PACKET_MMAP 来创建 ring buffer,用户空间可以直接映射上去,这样可以提高数据传输效率),之后就能触发 packet_setsockopt() 函数,PACKET_RX_RING / PACKET_TX_RING 选项都能控制页分配。
packet_setsockopt() -> packet_set_ring() -> alloc_pg_vec() -> alloc_one_pg_vec_page() -> __get_free_pages()
case PACKET_RX_RING:
case PACKET_TX_RING:
{
union tpacket_req_u req_u;
int len;
lock_sock(sk);
switch (po->tp_version) {
case TPACKET_V1:
case TPACKET_V2:
len = sizeof(req_u.req);
break;
case TPACKET_V3:
default:
len = sizeof(req_u.req3);
break;
}
if (optlen < len) {
ret = -EINVAL;
} else {
if (copy_from_sockptr(&req_u.req, optval, len))
ret = -EFAULT;
else
ret = packet_set_ring(sk, &req_u, 0, // <--------------
optname == PACKET_TX_RING);
}
release_sock(sk);
return ret;
}
使用 tpacket_req_u union 结构参数调用 packet_set_ring(),接着会调用 alloc_pg_vec(),page order 由 req->tp_block_size 决定,之后在 [1] 处调用 tp_block_nr 次 alloc_one_page_vec(),进而会调用 __get_free_pages() 来分配页。
static int packet_set_ring(struct sock *sk, union tpacket_req_u *req_u,
int closing, int tx_ring)
{
...
struct tpacket_req *req = &req_u->req;
...
order = get_order(req->tp_block_size); // order 基于 req->tp_block_size
pg_vec = alloc_pg_vec(req, order);
}
static struct pgv *alloc_pg_vec(struct tpacket_req *req, int order)
{
unsigned int block_nr = req->tp_block_nr;
struct pgv *pg_vec;
int i;
pg_vec = kcalloc(block_nr, sizeof(struct pgv), GFP_KERNEL | __GFP_NOWARN);
if (unlikely(!pg_vec))
goto out;
for (i = 0; i < block_nr; i++) {
pg_vec[i].buffer = alloc_one_pg_vec_page(order); // [1]
if (unlikely(!pg_vec[i].buffer))
goto out_free_pgvec;
}
out:
return pg_vec;
out_free_pgvec:
free_pg_vec(pg_vec, order, block_nr);
pg_vec = NULL;
goto out;
}
以上原语可以让我们耗尽 tp_block_nr 个 order-n page (n 由 tp_block_size 决定),关闭这个 socket fd 就能释放这 tp_block_nr 个页。虽然低权限用户无法调用这个函数,但是可以利用用户命名空间来绕过。还可以通过喷射普通对象来耗尽page,例如msg_msg,但是不太可靠。
2-3. fork噪声问题
调用路径:SYSCALL-fork -> kernel_clone() -> copy_process() -> dup_task_struct() & copy_process()
噪声问题:fork() 调用可能会分配一些无关对象,产生噪声。其主要调用了 kernel_clone(),注意,一般调用 fork 时没有设置 kernel_clone_args flag,就会导致分配很多对象。调用流程如下:
(1)
kernel_clone()->copy_process()(2)
copy_process()->dup_task_struct(),从自己的cache上分配task_struct对象 (依赖 order-2 page)。接着调用alloc_thread_stack_node(),如果没有可用的cached stacks,就会调用 __vmalloc_node_range() 分配16kb 连续线程用作内核线程栈,这样会分配 4个 order-0 page。(3)以上的
vmalloc会分配1个 kmalloc-64 来帮助设置 vmalloc 虚拟映射;接着,内核会从vmap_area_cachep分配2个vmap_areachunk,第1个是调用alloc_vmap_area()函数分配,第2个可能来自preload_this_cpu_lock()函数。- (4)
copy_process()->copy_creds(),具体会调用prepare_creds()分配 cred 结构(不能设置CLONE_THREADflag)。int copy_creds(struct task_struct *p, unsigned long clone_flags) { struct cred *new; int ret; #ifdef CONFIG_KEYS_REQUEST_CACHE p->cached_requested_key = NULL; #endif if ( #ifdef CONFIG_KEYS !p->cred->thread_keyring && #endif clone_flags & CLONE_THREAD ) { p->real_cred = get_cred(p->cred); get_cred(p->cred); alter_cred_subscribers(p->cred, 2); kdebug("share_creds(%p{%d,%d})", p->cred, atomic_read(&p->cred->usage), read_cred_subscribers(p->cred)); inc_rlimit_ucounts(task_ucounts(p), UCOUNT_RLIMIT_NPROC, 1); return 0; } new = prepare_creds(); // <--------- 分配 cred if (!new) return -ENOMEM; (5)
copy_process()之后会调用一系列copy_x()函数,x 表示进程标识,只要不设置CLONEflag,这些函数就会触发一个分配(通常从这些cache中分配,files_cache/fs_cache/sighand_cache/signal_cache)。最大的噪声是在设置mm_struct时(未设置CLONE_VMflag 时触发),会有一系列的分配,从vm_area_struct/anon_vma_chain/anon_vma这些cache中分配。所有这些分配都会从 order-0 page 取内存。retval = copy_semundo(clone_flags, p); if (retval) goto bad_fork_cleanup_security; retval = copy_files(clone_flags, p); if (retval) goto bad_fork_cleanup_semundo; retval = copy_fs(clone_flags, p); if (retval) goto bad_fork_cleanup_files; retval = copy_sighand(clone_flags, p); if (retval) goto bad_fork_cleanup_fs; retval = copy_signal(clone_flags, p); if (retval) goto bad_fork_cleanup_sighand; retval = copy_mm(clone_flags, p); if (retval) goto bad_fork_cleanup_signal; retval = copy_namespaces(clone_flags, p); if (retval) goto bad_fork_cleanup_mm; retval = copy_io(clone_flags, p); if (retval) goto bad_fork_cleanup_namespaces; retval = copy_thread(clone_flags, args->stack, args->stack_size, p, args->tls); if (retval) goto bad_fork_cleanup_io;- (6)最后,
copy_process在 here 分配1个 pid chunk,从 order-0 page 取内存。
在不同的系统配置中,以上的cache特性也不同,取决于 slab mergeability 和所需的 page size。
忽略page分配函数(例如 vmalloc),只看 slab 分配,1次fork会触发分配以下cache。
task_struct
kmalloc-64
vmap_area
vmap_area
cred_jar
files_cache
fs_cache
sighand_cache
signal_cache
mm_struct
vm_area_struct
vm_area_struct
vm_area_struct
vm_area_struct
anon_vma_chain
anon_vma
anon_vma_chain
vm_area_struct
anon_vma_chain
anon_vma
anon_vma_chain
vm_area_struct
anon_vma_chain
anon_vma
anon_vma_chain
vm_area_struct
anon_vma_chain
anon_vma
anon_vma_chain
vm_area_struct
anon_vma_chain
anon_vma
anon_vma_chain
vm_area_struct
vm_area_struct
pid
降低噪声:基于以上的代码分析和 clone manpage 资料,可以通过设置以下flag来降低噪声——CLONE_FILES | CLONE_FS | CLONE_VM | CLONE_SIGHAND,这样调用 fork 时就会触发以下slab分配:
task_struct
kmalloc-64
vmap_area
vmap_area
cred_jar
signal_cache
pid
注意,这里还会有4个order-0 page 分配(vmalloc导致),这个噪声是可接受的。还有一个问题,就是现在子进程不能写任何进程内存,因为和父进程共享了同一内存,所以我们需要使用shellcode来提权。
2-4. 提权
步骤:完整exploit 参见 exploit-cache.c。
(1)利用
setsockopt页喷方法,先申请很多 order-0 page 并释放两个其中1个,这样就有很多不会融合到 order-1 的 order-0 page 可用了;(2)接着使用以上flag多次调用
clone,触发分配 cred 对象;释放剩下的一半 order-0 page,喷射漏洞对象。注意,漏洞对象也可以可能溢出内核其他对象,可能导致崩溃,但是作者没有遇到这种情况。(3)触发所有漏洞对象的溢出,前4字节(为1)是伪造
cred->usage以确保通过内核检查,后2字节(为0)篡改 uid 为0。触发溢出后,通过pipe通知所有fork,检查自身的uid,提权成功则触发执行shell。
测试截图:
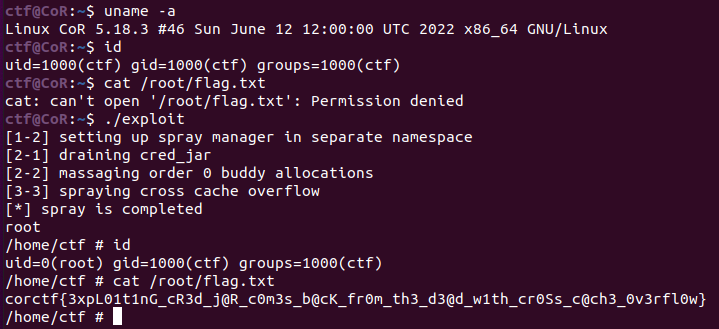
3. 其他利用方法
其他利用方法:
(1)采用cross-cache
seq_file对象 进行任意读,来泄露驱动地址,并构造任意释放来释放castaway_arr来构造UAF 和任意写原语;(2)pql 也是采用 cross-cache 篡改cred,不过方法更稳定,先调用
setuid再调用fork()。setuid会调用prepare_creds()并分配 cred 对象来预填充cred_jarslab,这样触发分配的页,产生的噪声就很少,setuid()执行完毕会释放该 cred 对象,然后立刻调用fork()重新获取该cred对象即可。long __sys_setuid(uid_t uid) { struct user_namespace *ns = current_user_ns(); const struct cred *old; struct cred *new; ... new = prepare_creds(); // [1] 先分配一个 cred 进行预填充 ... old = current_cred(); ... new->fsuid = new->euid = kuid; // [2] 预填充 ... flag_nproc_exceeded(new); return commit_creds(new); // [3] 应用 error: abort_creds(new); // [4] 释放 return retval; }
SYSCALL_DEFINE2-setuid -> __sys_setuid() -> prepare_creds() 由于分配cred结构的直接函数是 prepare_creds(),所以pql 可能也是从 prepare_creds() 引用点找到 setuid 调用的。
作者也从未想过 setuid 会分配对象,还以为它只会进行 permission 检查,看来查看源码才是王道。
测试真实环境:作者还在真实环境上测试了这个利用方法是否有效,环境是 a single core default Ubuntu HWE 20.04 server VM with 4 gbs of RAM and KVM enabled,只需要修改两个地方,提权仍然有效(成功率50%)。
首先将
FINAL_PAGE_SPRAY宏设置为 50,需要多喷点漏洞对象;再就是需要适应 Ubuntu 的
CONFIG_SCHED_STACK_END_CHECK选项,由于溢出写入在内核栈里,payload会触发 stack end check 导致失败,检查语句如下。STACK_END_MAGIC = 0x57AC6E9D,只需将payload前4字节1111替换为0x57AC6E9D即可。#define task_stack_end_corrupted(task) \ (*(end_of_stack(task)) != STACK_END_MAGIC)
在多核配置下,512 字节的chunk会从 order-1 page 取内存,需更改堆喷策略(还要绑定CPU核来执行)。
其他资料:最近 All Roads Lead to GKE’s Host 深入介绍了 cross cache; DirtyCred Blackhat 介绍了一种新的方法来篡改 cred,利用 UAF/double-free/arbitrary-free 漏洞和 cross-cache。
参考
cache-of-castaways —— 题目环境
https://ctftime.org/task/23289
文档信息
- 本文作者:bsauce
- 本文链接:https://bsauce.github.io/2022/11/07/castaways/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)