【漏洞分析】CVE-2021-0920 Linux内核垃圾回收机制中的竞争UAF漏洞
漏洞发现:该漏洞早在2016年被 RedHat 内核开发人员发现并披露,但 Linux 内核社区直到 2021 年重新报告后才对该漏洞进行修补(patch)。Google的威胁分析小组(Threat Analysis Group)发现该漏洞在野外被使用,可以绕过沙箱和提权,结合Chrome和三星浏览器漏洞利用,就能够远程root三星设备。被攻击的目标包括三星 S10 和 S20,野外利用样本能绕过 CONFIG_ARM64_UAO,实现任意读/写原语,绕过三星 RKP 提升至 root。
主要内容:本文分析了 SCM_RIGHTS 的内核实现以及 Linux 内核垃圾回收器的设计和实现,此外,还分析了MSG_PEEK 标志与recvmsg系统调用的执行流程,以及导致竞争而触发UAF漏洞的过程。该漏洞早在 2016 年就被发现,但 Linux 内核社区当时并未接受该补丁,任何人看到这封公开的邮件都有可能利用该漏洞来提权。
CVE-2021-0920漏洞原理:CVE-2021-0920 是由于 SCM_RIGHTS 的垃圾回收系统(Garbage Collection)中的竞争条件而导致的UAF。SCM_RIGHTS 是一种控制消息,它允许 unix socket将打开的文件描述符从一个进程传输到另一个进程。换句话说,sender发送文件描述符,然后 receiver 从 sender 获取文件描述符。这种文件描述符的传递增加了 file 结构引用计数的复杂性。为了解决该问题,Linux 内核设计了一个特殊的垃圾回收系统。CVE-2021-0920 是此垃圾回收系统中的一个漏洞。通过在垃圾回收过程中赢得竞争条件,攻击者可以获得socket缓冲区上也即sk_buff对象的 UAF。接下来,将详细介绍 SCM_RIGHTS 垃圾回收系统和漏洞原理,本文基于Linux 4.14 内核。
1. UNIX_GC垃圾回收机制介绍
1-1. file 结构引用计数
file结构:Linux 内核使用 file 结构来表示一个打开的文件,用户空间每打开一个文件,内核就会创建一个相应的file结构体。本质上,文件描述符就是一个索引,可通过 struct files_struct 中的 file 指针数组(files_struct->fd_array)来找到对应的 file 结构指针。file 结构中保存了大量信息 ,包括文件中的当前位置、访问模式、file_operations 结构、供底层代码使用的 private_data 指针等。
引用计数:和其他内核结构一样,可以存在多个对file 结构的引用。例如,将文件描述符传给 dup() 将分配指向相同 file 结构的第2个文件描述符。内核用 file->f_count 成员来记录其引用数目,如果某 file 结构不再被使用则将其释放。只要使用了该文件(创建引用,例如调用 dup() 复制文件描述符、fork新进程、开始进行I/O操作)就增加 file->f_count 引用计数;使用完之后移除引用可通过调用 close() / exit(),就减少 file->f_count 引用计数;当引用计数为0时,释放该 file 结构。
内核中很多操作都能创建对file 结构的引用,例如,调用read()将在操作期间保存一个引用,以确保file结构一直存在;mount挂载 file 中的文件系统将创建一个引用,直到unmount卸载文件系统。还包括后面介绍的通过sock的scm功能发送文件给另一端/io_uring的注册文件等。
实际能引起文件引用计数变化的内核函数有:
fget():通过文件描述符获取struct file,并把文件引用计数+1get_file():传入是struct file,返回struct file,该函数单纯的把文件引用计数+1fput():减少一次文件引用计数,如果减少到0则会释放文件的struct file结构
1-2. SCM_RIGHTS 消息
SCM_RIGHTS控制消息:Linux 开发者可以使用 sendmsg 系统调用发送 SCM_RIGHTS 数据(参见https://man7.org/linux/man-pages/man7/unix.7.html)将文件描述符 fd 从一个进程共享到另一个进程(该功能的本意是有权限打开文件的进程打开文件然后传递给没权限打开的进程使用,和dup2()不同的是,传递到对端的文件描述符数字和本端不一样)。当sender进程将文件描述符传递给另一个进程receiver时,SCM_RIGHTS 将创建一个对 file 结构的引用(该 file 结构指针放在receiver端的 sock->sk_receive_queue 队列上),这样即使receiver进程尚未接收到文件描述符,sender也可以立即关闭该文件描述符。当文件描述符处于“queued” 排队状态(表示sender已发送并关闭了该 fd,但receiver尚未接收 fd 并取得所有权)时,需要进行专门的垃圾回收。为了跟踪这种“queued”状态,文章 io_uring, SCM_RIGHTS, and reference-count cycles 很好地解释了SCM_RIGHTS 引用计数和垃圾回收原理。
内存泄露问题:如果两个文件描述符 FD1 和 FD2 都把自己发送给对方,在都没有接收到文件描述符的情况下关闭 FD1 和 FD2,那么这两个 file 结构部将永远无法释放,造成内存泄露。所以要引入Linux垃圾回收机制,采用 inflight 飞行计数来统计正在被发送的文件描述符,识别内核中的不可破循环,并释放不可破循环中的 file 对象。
1-3. 发送文件描述符
scm_cookie->fp存储传递中的 file 结构:前面提到,unix socket 使用系统调用 sendmsg 将文件描述符发送到另一个socket。我们将从sender的角度出发,来解释 SCM_RIGHTS 期间发生的引用计数。首先是函数 unix_stream_sendmsg(),实现了sendmsg 调用的主要功能。为了实现 SCM_RIGHTS 功能,内核使用 scm_fp_list 结构来管理所有传输的 file 结构(也即要传递的 file 结构指针列表)。
struct scm_fp_list {
short count;
short max;
struct user_struct *user;
struct file *fp[SCM_MAX_FD]; // <--- 存储传递的 file
};
unix_stream_sendmsg() 先调用 scm_send() 来初始化 scm_fp_list 结构,并由栈上的 scm_cookie 结构采用双链表来保存。 scm_cookie->fp (scm_fp_list)
struct scm_cookie {
struct pid *pid; /* Skb credentials */
struct scm_fp_list *fp; /* Passed files */ // <--- 传递中的 file
struct scm_creds creds; /* Skb credentials */
#ifdef CONFIG_SECURITY_NETWORK
u32 secid; /* Passed security ID */
#endif
};
初始化sk_buff->fp:具体调用链是 scm_send() -> __scm_send() -> scm_fp_copy(),从用户空间读取文件描述符并初始化 scm_cookie->fp (其中可以包含最多 SCM_MAX_FD 个 file 结构)。注意,scm_fp_copy() 初始化 scm_cookie->fp 时会增加文件引用计数(调用 fget_raw(),只表示scm正在处理这个文件),所以在unix_stream_sendmsg() 结尾会调用 scm_destroy(&scm) 将刚刚初始化scm时增加的文件引用计数减少(调用 fput())。
由于 Linux 内核使用 sk_buff (也称为socket缓冲区或skb )对象来管理所有类型的socket数据报,因此内核还需要调用 unix_scm_to_skb() 函数将 scm_cookie->fp 文件列表绑定到相应的skb 对象,并增加文件引用计数(调用 scm_fp_dup() )和飞行计数(调用 unix_inflight())。完成绑定功能的调用链是 unix_stream_sendmsg() -> unix_scm_to_skb() -> unix_attach_fds()。
int unix_attach_fds(struct scm_cookie *scm, struct sk_buff *skb)
{
int i;
if (too_many_unix_fds(current))
return -ETOOMANYREFS;
// [1] 先调用 scm_fp_dup(),对每一个文件增加引用计数
UNIXCB(skb).fp = scm_fp_dup(scm->fp);
if (!UNIXCB(skb).fp)
return -ENOMEM;
for (i = scm->fp->count - 1; i >= 0; i--)
unix_inflight(scm->fp->user, scm->fp->fp[i]); // [2] 对每一个文件调用 unix_inflight() 增加飞行计数,参见 1-5(2) 节
return 0;
}
EXPORT_SYMBOL(5unix_attach_fds);
增加文件引用计数:scm_fp_dup() 会增加正在传递的文件描述符的引用计数 file->f_count(表示sock->sk_receive_queue 接收队列引用了该文件,文件正在发送中),所以即使sender端关闭了该文件描述符,文件依然有效。
struct scm_fp_list *scm_fp_dup(struct scm_fp_list *fpl)
{
struct scm_fp_list *new_fpl;
int i;
if (!fpl)
return NULL;
new_fpl = kmemdup(fpl, offsetof(struct scm_fp_list, fp[fpl->count]),
GFP_KERNEL);
if (new_fpl) {
for (i = 0; i < fpl->count; i++)
get_file(fpl->fp[i]); // <--- 增加正在传递的文件描述符的引用计数
new_fpl->max = new_fpl->count;
new_fpl->user = get_uid(fpl->user);
}
return new_fpl;
}
EXPORT_SYMBOL(scm_fp_dup);
具体案例:假设有 socket A 和 B,A将自身传递给B。在发送 SCM_RIGHTS 数据包后,sender 新分配的skb将附加到 B 的 sock->sk_receive_queue 中 ,该队列存储接收到的数据报。
unix_stream_sendmsg() 创建包含 scm_fp_list 结构的 sk_buff,scm_fp_list 保存传输文件A 的 fp 指针。 sk_buff 被追加到 receiver 队列,A 的引用计数为 2,B的引用计数仍为1。
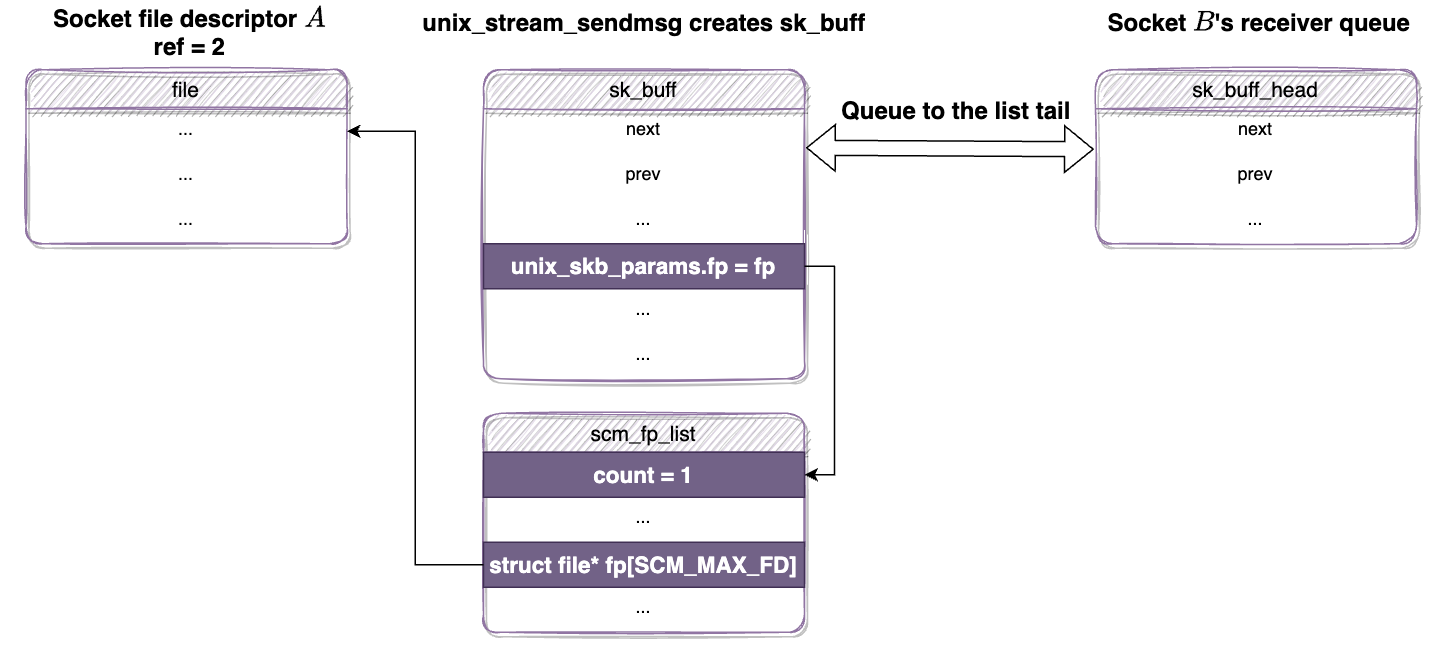
1-4. 接收文件描述符
接收端调用 unix_stream_read_generic() (暂且不讨论MSG_PEEK 标志,只关注正常routine)。首先,内核调用 skb_peek() 从 sk_receive_queue 中获取当前的skb 。然后,由于skb中保存了 scm_fp_list 结构,内核将调用 unix_detach_fds() 解析来自skb的传输 file 结构,并从 sk_receive_queue 中清除skb:
static int unix_stream_read_generic(struct unix_stream_read_state *state,
bool freezable)
{
struct scm_cookie scm;
struct socket *sock = state->socket;
struct sock *sk = sock->sk;
struct unix_sock *u = unix_sk(sk);
...
do {
...
last = skb = skb_peek(&sk->sk_receive_queue); // 获取当前skb
...
if (!(flags & MSG_PEEK)) {
UNIXCB(skb).consumed += chunk;
sk_peek_offset_bwd(sk, chunk);
if (UNIXCB(skb).fp)
unix_detach_fds(&scm, skb); // <--- 解析来自skb 的传输 `file` 结构
if (unix_skb_len(skb))
break;
skb_unlink(skb, &sk->sk_receive_queue);
consume_skb(skb);
if (scm.fp)
break;
}
...
}
if (state->msg)
scm_recv(sock, state->msg, &scm, flags); // <--- 接收:遍历文件描述符列表`scm->fp`并安装新的文件描述符
else
scm_destroy(&scm);
out:
return copied ? : err;
}
void unix_detach_fds(struct scm_cookie *scm, struct sk_buff *skb)
{
int i;
scm->fp = UNIXCB(skb).fp; // 解析来自skb 的传输 `file` 结构
UNIXCB(skb).fp = NULL;
for (i = scm->fp->count-1; i >= 0; i--)
unix_notinflight(scm->fp->user, scm->fp->fp[i]);
}
EXPORT_SYMBOL(unix_detach_fds);
scm_recv() -> scm_detach_fds() 遍历传递的文件描述符列表 scm->fp 并为相应地 receiver 安装新的文件描述符:
void scm_detach_fds(struct msghdr *msg, struct scm_cookie *scm)
{
...
for (i=0, cmfptr=(__force int __user *)CMSG_DATA(cm); i<fdmax;
i++, cmfptr++)
{
struct socket *sock;
int new_fd;
err = security_file_receive(fp[i]);
if (err)
break;
err = get_unused_fd_flags(MSG_CMSG_CLOEXEC & msg->msg_flags
? O_CLOEXEC : 0);
if (err < 0)
break;
new_fd = err;
err = put_user(new_fd, cmfptr);
if (err) {
put_unused_fd(new_fd);
break;
}
/* Bump the usage count and install the file. */
sock = sock_from_file(fp[i], &err);
if (sock) {
sock_update_netprioidx(&sock->sk->sk_cgrp_data);
sock_update_classid(&sock->sk->sk_cgrp_data);
}
fd_install(new_fd, get_file(fp[i])); // <--- 安装新的文件描述符
}
...
__scm_destroy(scm); // 所有文件的使用计数都增加了,减少文件引用计数并释放list
}
安装文件描述符后,__scm_destroy() 清除分配的 scm->fp 并减少每个传输 file 结构的文件引用计数:
void __scm_destroy(struct scm_cookie *scm)
{
struct scm_fp_list *fpl = scm->fp;
int i;
if (fpl) {
scm->fp = NULL;
for (i=fpl->count-1; i>=0; i--)
fput(fpl->fp[i]); // receiver 接收文件后,就减少其引用计数
free_uid(fpl->user);
kfree(fpl);
}
}
EXPORT_SYMBOL(__scm_destroy);
1-5. 引用计数和飞行计数
(1)内存泄露问题与飞行计数
前面提到,当使用 SCM_RIGHTS 传递文件描述符时,其引用计数会立即递增。一旦receiver socket 接收并安装了传递的文件描述符,引用计数就会减少。
那么如果在sender发送文件描述符之后,在receiver 接收文件描述符之前关闭文件描述符,会发生什么呢?
假设如下场景:
- (1)该进程创建socket A 和 B 。
- (2)A 将socket A 发送到 socket B 。
- (3)B 将socket B 发送 到socket A 。
- (4)关闭 A 。
- (5)关闭 B。
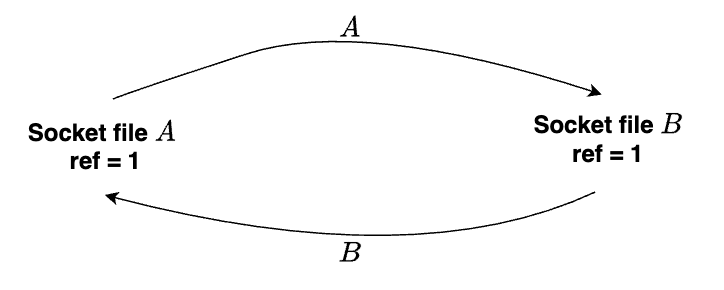
在接收传递的文件描述符之前,关闭两个socket。A 和 B 的引用计数均为 1,并且无法进一步减少,因为当各自的进程关闭它们时,它们已从内核 fd 表中删除。因此内核无法释放两个skb和sock结构,形成一个不可破的循环。Linux 内核垃圾回收系统就是为了防止这种情况下的内存耗尽,引入inflight飞行计数是为了识别潜在的垃圾。每次发送 SCM_RIGHTS 数据报而增加引用计数时,飞行计数也将增加。
(2)源码分析-增加飞行计数
调用链— unix_stream_sendmsg() -> unix_scm_to_skb() -> unix_attach_fds() -> unix_inflight()。当采用 SCM_RIGHTS 数据报发送文件描述符时,Linux 内核将其 unix_sock 放入全局列表 gc_inflight_list 中,并递增 unix_tot_inflight(表示飞行中的socket总数)。然后,内核递增 u->unix_inflight 以记录每个文件描述符的飞行计数(表示正在被传递的数目):
void unix_inflight(struct user_struct *user, struct file *fp)
{
struct sock *s = unix_get_socket(fp); // [1] 只有socket 和io_uring的fd才能找到sock
spin_lock(&unix_gc_lock);
if (s) { // [2] 对于sock类型文件则增加飞行计数
struct unix_sock *u = unix_sk(s);
if (atomic_long_inc_return(&u->inflight) == 1) {
BUG_ON(!list_empty(&u->link));
list_add_tail(&u->link, &gc_inflight_list); // [2] 将 unix_sock 放入全局列表 gc_inflight_list
} else {
BUG_ON(list_empty(&u->link));
}
/* Paired with READ_ONCE() in wait_for_unix_gc() */
WRITE_ONCE(unix_tot_inflight, unix_tot_inflight + 1); // [2] 递增unix_tot_inflight (表示飞行中的socket总数)
}
user->unix_inflight++; // 用户统计飞行计数增加
spin_unlock(&unix_gc_lock);
}
(3)不可破循环示例
当文件描述符A将自己发送给文件描述符B时,以下是 sk_buff 的状态(文件描述符A的引用计数和飞行计数都增加了),文件描述符A的引用计数为2,飞行计数为1。对于接收方文件描述符B,文件引用计数为1,飞行计数为0。
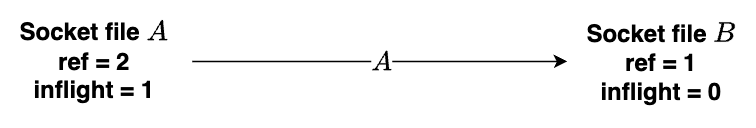
当从另一端接收到socket文件描述符时,unix_sock->inflight 计数将减少。
再次回顾关闭系统调用之前的引用计数循环场景。这个循环是可打破的,因为任何socket文件都可以接收传输的文件并打破引用循环,关闭A和B之前的可破循环如下所示:
文件描述符 A 将自身发送到文件描述符 B,反之亦然。 文件描述符A和B的飞行计数都是1,文件引用计数都是2。
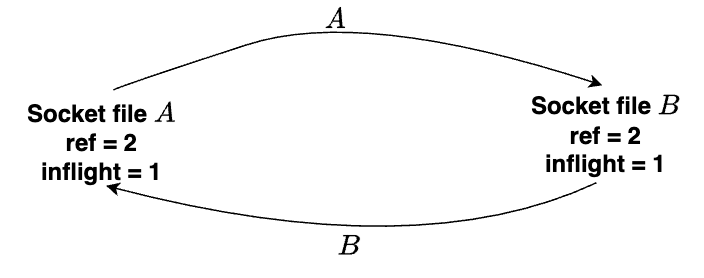
关闭两个文件描述符后,循环变得牢不可破(无法通过接收文件描述符来打破循环,减少引用计数),A和B的引用计数都等于每个socket文件描述符的飞行计数,这是可能存在垃圾的迹象:
(4)可破循环示例
场景2。假设我们有socket A、B 和𝛼 :
- A 将socket A 发送到socket B。
- B 将socket B 发送到socket A 。
- B 将socket B 发送到socket 𝛼 。
- 𝛼 将socket 𝛼 发送到socket B。
- 关闭 A。
- 关闭 B。
A / B / 𝛼 形成一个可破的循环。这个循环是可打破的,因为我们可以从socket文件描述符 𝛼 得到新安装的文件描述符 B’ , 从 B’ 得到新安装的文件描述符 A’(可以通过接收文件描述符来打破循环,减少引用计数)。
1-6. 垃圾回收
垃圾回收机制可参见 io_uring, SCM_RIGHTS, and reference-count cycles。
(1)识别不可破引用循环
搜索不可破循环的流程:如果引用计数和飞行计数相等,则该 file 结构可能属于不可破循环。首先,内核找到所有飞行中的socket(SCM_RIGHTS数据报中包含其引用的socket),也即f_count 和 inflight 值相等的socket。然后,计算对每个socket的引用有多少来自附加到该集合中socket的 SCM_RIGHTS 数据报,如果某socket具有来自集合外部的引用,则表明其可达并且可以排除了。如果某socket从外部可以访问到,并且有某个 SCM_RIGHTS 数据报附加到该socket,则该数据报中包含的文件也是可访问的,可以排除。
经过迭代搜索和排除之后,内核最终会找到一组飞行中的socket,这些socket仅被集合内socket的 SCM_RIGHTS 数据报所引用。该 file 结构循环中,各自包含对彼此的唯一引用。只要从sock->sk_receive_queue接收队列中删除这些数据报,释放它们持有的引用,就能打破循环,释放这些socket。
代码流程:SCM_RIGHTS 垃圾回收系统中,unix_gc() 函数负责识别不可破的引用循环,过程如下。
- [1] 首先,将任何引用计数等于其飞行计数的
unix_sock对象添加到gc_candidates列表中(作为垃圾回收的候选)。 - [2] 然后,确定 socket 是否被
gc_candidates列表之外的任何 socket 所引用。如果是,那么它是可达的,就从gc_candidates列表中删除它和它引用的任何socket。重复该过程,直到找不到可到达的socket。(实际是调用 scan_children() 和函数指针 dec_inflight 来遍历每个候选socket的sk->receive_queue接收队列,减少每个传递的文件描述符(位于gc_candidates列表内的文件描述符)的飞行计数;迭代结束后,如果还有候选socket的飞行计数大于0,则说明其存在外部引用,需从gc_candidates列表排除;需调用 scan_children() -> scan_inflight() 遍历gc_candidates列表中每个传输文件的接收队列sock->sk_receive_queue,并递增恢复飞行计数) - [3] 迭代结束后,
gc_candidates列表中的socket只被gc_candidates列表内的socket所引用。
void unix_gc(void)
{
struct unix_sock *u;
struct unix_sock *next;
struct sk_buff_head hitlist;
struct list_head cursor;
LIST_HEAD(not_cycle_list);
...
list_for_each_entry_safe(u, next, &gc_inflight_list, link) { // [1]
long total_refs;
long inflight_refs;
total_refs = file_count(u->sk.sk_socket->file);
inflight_refs = atomic_long_read(&u->inflight);
BUG_ON(inflight_refs < 1);
BUG_ON(total_refs < inflight_refs);
if (total_refs == inflight_refs) { // 若引用计数等于飞行计数,则放入`gc_candidates`列表
list_move_tail(&u->link, &gc_candidates);
__set_bit(UNIX_GC_CANDIDATE, &u->gc_flags); // 设置两个flag(UNIX_GC_CANDIDATE/UNIX_GC_MAYBE_CYCLE)
__set_bit(UNIX_GC_MAYBE_CYCLE, &u->gc_flags);
}
}
list_for_each_entry(u, &gc_candidates, link) // [2] 遍历每个候选socket的 `sk->receive_queue`接收队列,减少每个传递的文件描述符(位于`gc_candidates` 列表内的文件描述符)的飞行计数
scan_children(&u->sk, dec_inflight, NULL);
list_add(&cursor, &gc_candidates);
while (cursor.next != &gc_candidates) {
u = list_entry(cursor.next, struct unix_sock, link);
/* Move cursor to after the current position. */
list_move(&cursor, &u->link);
if (atomic_long_read(&u->inflight) > 0) { // [3] 迭代结束后,`gc_candidates`剩下的 socket 如果飞行计数仍大于0,则说明存在外部引用,是可达的,需从`gc_candidates`列表移除,并恢复相关的飞行计数
list_move_tail(&u->link, ¬_cycle_list); // 将候选者放入 `not_cycle_list`,并遍历gc_candidates列表中每个传输文件gc_inflight_list的接收队列sock->sk_receive_queue,并递增恢复其飞行计数
__clear_bit(UNIX_GC_MAYBE_CYCLE, &u->gc_flags);
scan_children(&u->sk, inc_inflight_move_tail, NULL); // 递增恢复飞行计数
}
}
list_del(&cursor);
skb_queue_head_init(&hitlist); // 现在`gc_candidates`列表中只包含垃圾socket,恢复其飞行计数
list_for_each_entry(u, &gc_candidates, link)
scan_children(&u->sk, inc_inflight, &hitlist);
/* not_cycle_list contains those sockets which do not make up a
* cycle. Restore these to the inflight list.
*/
while (!list_empty(¬_cycle_list)) { // 将候选者从 not_cycle_list 移回到 gc_inflight_list
u = list_entry(not_cycle_list.next, struct unix_sock, link);
__clear_bit(UNIX_GC_CANDIDATE, &u->gc_flags);
list_move_tail(&u->link, &gc_inflight_list);
}
spin_unlock(&unix_gc_lock);
__skb_queue_purge(&hitlist); // [4] 调用 __skb_queue_purge() 清除垃圾
spin_lock(&unix_gc_lock);
...
}
__skb_queue_purge() 函数负责清除垃圾,释放垃圾队列中每一个skb,并把 skb->cb.fp 中的文件调用scm_destroy() 释放 :
void skb_queue_purge(struct sk_buff_head *list);
static inline void __skb_queue_purge(struct sk_buff_head *list) // 删除 &sk_buff 列表中的所有缓冲区,并删除其引用。本函数不使用列表锁,所以调用者必须获得相关的锁才能使用它。
{
struct sk_buff *skb;
while ((skb = __skb_dequeue(list)) != NULL)
kfree_skb(skb);
}
有两种方式可以触发垃圾回收:
- 如果有超过 16,000 个飞行socket,则在
sendmsg()函数开头调用 wait_for_unix_gc() - 当关闭一个socket文件描述符时,内核将直接调用 unix_gc()。
注意, unix_gc() 不是抢占式的。如果垃圾回收已经在运行,内核将不会执行另一个 unix_gc() 调用。
(2)案例分析
现在,通过一个可破循环来测试一下,假设有一对 socket $f0_0$ 和 $f0_1$,以及单个socket 𝛼:
- (1)socket $f0_0$ 将 socket $f0_0$ 发送到 socket $f0_1$
- (2)socket $f0_1$ 将 socket $f0_1$ 发送到 socket 𝛼
- (3)关闭 $f0_0$
- (4)关闭 $f0_1$
在开始垃圾回收前,socket文件描述符的状态如下,构成可破循环:
- $f0_0$: ref = 1, inflight = 1
- $f0_1$: ref = 1, inflight = 1
- 𝛼 : ref = 1, inflight = 0

在垃圾回收时,$f0_0$ 和 $f0_1$ 被视为垃圾候选。$f0_0$ 的飞行计数降为零,但 $f0_1$ 的飞行计数仍为 1,因为𝛼 不是候选者。因此,内核将从 $f0_1$ 的 接收队列中恢复飞行计数。结果,$f0_0$ 和 $f0_1$ 不再被视为垃圾。
2. CVE-2021-0920 漏洞分析
当用户通过 recvmsg(不含 MSG_PEEK 标志)接收到 SCM_RIGHTS 消息时,内核将等待正在进行的垃圾回收完成。但是,如果打开了 MSG_PEEK 标志,内核将增加传输文件结构的引用计数,而不与任何正在进行的垃圾回收过程同步(问题就在于没有实施同步机制)。这可能会导致内部垃圾回收状态的不一致,使垃圾回收器将非垃圾的 sock 对象错误识别为要清除的垃圾。
2-1. 调用 recvmsg—不带 MSG_PEEK 标志(引用计数不变,减少飞行计数)
在未设置 MSG_PEEK 标志时,unix_stream_read_generic() 函数负责解析 SCM_RIGHTS 消息并管理文件飞行计数 。然后,unix_stream_read_generic() 调用 unix_detach_fds() 来减少飞行计数,并从skb中清除传递的文件描述符列表 scm_fp_list。
void unix_detach_fds(struct scm_cookie *scm, struct sk_buff *skb)
{
int i;
scm->fp = UNIXCB(skb).fp;
UNIXCB(skb).fp = NULL; // 清空 fp 指针
for (i = scm->fp->count-1; i >= 0; i--)
unix_notinflight(scm->fp->user, scm->fp->fp[i]); // 减少飞行计数,并从skb中清除传递的文件描述符列表 `scm_fp_list`
}
EXPORT_SYMBOL(unix_detach_fds);
unix_detach_fds() -> unix_notinflight() 负责减少飞行计数,功能和 unix_inflight() 恰好相反。
void unix_notinflight(struct user_struct *user, struct file *fp)
{
struct sock *s = unix_get_socket(fp);
spin_lock(&unix_gc_lock);
if (s) {
struct unix_sock *u = unix_sk(s);
BUG_ON(!atomic_long_read(&u->inflight));
BUG_ON(list_empty(&u->link));
if (atomic_long_dec_and_test(&u->inflight)) // 减少飞行计数
list_del_init(&u->link);
/* Paired with READ_ONCE() in wait_for_unix_gc() */
WRITE_ONCE(unix_tot_inflight, unix_tot_inflight - 1);
}
user->unix_inflight--;
spin_unlock(&unix_gc_lock);
}
之后 unix_stream_read_generic() 调用 skb_unlink() 和 consume_skb() 来释放当前skb。调用链 consume_skb() -> __kfree_skb() -> skb_release_all() -> skb_release_head_state() -> skb->destructor 实际会调用 unix_destruct_scm() 函数:
void unix_destruct_scm(struct sk_buff *skb)
{
struct scm_cookie scm;
memset(&scm, 0, sizeof(scm));
scm.pid = UNIXCB(skb).pid;
if (UNIXCB(skb).fp)
unix_detach_fds(&scm, skb); // !!!!!!! 漏洞点,由于
/* Alas, it calls VFS */
/* So fscking what? fput() had been SMP-safe since the last Summer */
scm_destroy(&scm);
sock_wfree(skb);
}
EXPORT_SYMBOL(unix_destruct_scm);
问题:实际上不会执行 unix_detach_fds() 函数,因为 UNIXCB(skb).fp 已经被 unix_detach_fds() 清除。最后,unix_stream_read_generic() -> scm_recv() -> scm_detach_fds() 调用fd_install(new_fd, get_file(fp[i])) 来安装新的文件描述符。
2-2. 调用 recvmsg—带 MSG_PEEK 标志(增加引用计数,飞行计数不变)
如果设置了MSG_PEEK标志,则 recvmsg 过程不同。在接收时用MSG_PEEK 标志来“查看”消息,但数据被视为未读。unix_stream_read_generic() -> unix_peek_fds() -> scm_fp_dup() 调用的是 scm_fp_dup() 而不是 unix_detach_fds() 。这会增加飞行文件的引用计数。
static int unix_stream_read_generic(struct unix_stream_read_state *state,
bool freezable)
{
struct scm_cookie scm;
...
if (!(flags & MSG_PEEK)) {
...
} else {
/* It is questionable, see note in unix_dgram_recvmsg.
*/
if (UNIXCB(skb).fp)
unix_peek_fds(&scm, skb);
...
}
}
static void unix_peek_fds(struct scm_cookie *scm, struct sk_buff *skb)
{
scm->fp = scm_fp_dup(UNIXCB(skb).fp);
...
}
struct scm_fp_list *scm_fp_dup(struct scm_fp_list *fpl)
{
struct scm_fp_list *new_fpl;
int i;
if (!fpl)
return NULL;
new_fpl = kmemdup(fpl, offsetof(struct scm_fp_list, fp[fpl->count]),
GFP_KERNEL);
if (new_fpl) {
for (i = 0; i < fpl->count; i++)
get_file(fpl->fp[i]); // 增加飞行文件的引用计数
new_fpl->max = new_fpl->count;
new_fpl->user = get_uid(fpl->user);
}
return new_fpl;
}
EXPORT_SYMBOL(scm_fp_dup);
由于数据应该被视为未读,所以当设置MSG_PEEK标志时, skb 不会被unlink和释放。但是,receiver 端仍将获得飞行socket的新文件描述符。
2-3. recvmsg示例
具体示例,假设有socket对 $f0_0$ / $f0_1$ 和 $f1_0$ / $f1_1$,该程序执行以下操作:
- $f0_0$ → [$f0_0$] → $f0_1$ (表示 $f0_0$ 发送 [$f0_0$] 到 $f0_1$)
- $f1_0$ → [$f0_0$] → $f1_1$
- close($f0_0$)
$f0_0$ / $f0_1$ 和 $f1_0$ / $f1_1$ 形成一个可破的循环
状态如下:
- inflight($f0_0$) = 2, ref($f0_0$) = 2
- inflight($f0_1$) = 0, ref($f0_1$) = 1
- inflight($f1_0$) = 0, ref($f1_0$) = 1
- inflight($f1_1$) = 0, ref($f1_1$) = 1
如果现在发生垃圾回收过程,在调用recvmsg之前,内核会将$f0_0$作为垃圾候选者。但是,$f0_0$不会更改飞行计数,内核也不会清除任何垃圾。
接着,如果 $f0_1$ 调用recvmsg(带MSG_PEEK标志),则$f0_1$的接收队列保持不变(未被清除)并且飞行计数不会减少。$f0_1$ 获得一个新的文件描述符 $f0_0$’ ,它会增加 $f0_0$ 上的文件引用计数:
状态如下:
- inflight($f0_0$) = 2, ref($f0_0$) = 3
- inflight($f0_1$) = 0, ref($f0_1$) = 1
- inflight($f1_0$) = 0, ref($f1_0$) = 1
- inflight($f1_1$) = 0, ref($f1_1$) = 1
接着,$f0_1$ 调用recvmsg(不带MSG_PEEK标志),$f0_1$的接收队列被清空移除,$f0_1$还获得一个新的文件描述符$f0_0$’‘ :
状态如下:
- inflight($f0_0$) = 2, ref($f0_0$) = 3
- inflight($f0_1$) = 0, ref($f0_1$) = 1
- inflight($f1_0$) = 0, ref($f1_0$) = 1
- inflight($f1_1$) = 0, ref($f1_1$) = 1
2-4. skb UAF漏洞
从 high-level 来看,由于 MSG_PEEK 和垃圾回收器不同步,导致 Linux 垃圾回收的内部状态不确定。这里可能导致竞争,垃圾回收器可以将飞行中的socket视为垃圾候选,而同时带MSG_PEEK标志接收时会递增文件引用。因此,垃圾回收器可能会清除候选者,释放socket缓冲区,而receiver端可能会安装文件描述符,从而导致 skb 对象的 UAF。
接下来看看漏洞触发过程。首先,分配如下socket对和单个socket 𝛼 :
- $f0_0$ / $f0_1$
- $f1_0$ / $f1_1$
- $f2_0$ / $f2_1$
- $f3_0$ / $f3_1$
- socket 𝛼 (实际上可能有数千个𝛼 用于延长垃圾回收过程,以逃避稍后将介绍的BUG_ON检查)。
现在,程序执行以下操作:
在调用recvmsg之前关闭以下文件描述符,只留下 $f2_0$ / $f2_1$ :
- close($f0_0$)
- close($f0_1$)
- close($f1_1$)
- close($f1_0$)
- close($f3_0$)
- close($f3_1$)
- close(𝛼)
状态如下:
- inflight($f0_0$) = N + 1, ref($f0_0$) = N + 1
- inflight($f0_1$) = 2, ref($f0_1$) = 2
- inflight($f1_0$) = 3, ref($f1_0$) = 3
- inflight($f1_1$) = 1, ref($f1_1$) = 1
- inflight($f2_0$) = 0, ref($f2_0$) = 1
- inflight($f2_1$) = 0, ref($f2_1$) = 1
- inflight($f3_1$) = 1, ref($f3_1$) = 1
- inflight(𝛼) = 1, ref(𝛼) = 1
如果正在进行垃圾回收过程,内核将进行以下检查:
- 将$f0_0$、$f0_1$、$f1_0$、$f1_1$、$f3_1$、𝛼 列为垃圾候选对象,减少每个接收队列中候选对象的飞行计数;
- 由于$f2_1$不被视为候选者,因此$f1_1$的飞行计数仍大于零;
- 递归恢复飞行计数;
- 没有垃圾。
以下操作可能会引发竞争,并导致 skb UAF:
- (1)$f2_1$调用recvmsg(带MSG_PEEK标志) ,获得$f1_1$’;
- (2)$f1_1$调用recvmsg(带MSG_PEEK标志),获得$f1_0$’。
同时并发进行如下操作:
(1)$f1_1$调用recvmsg(不带MSG_PEEK标志),获得$f1_0$’‘;
(2)$f1_0$’调用recvmsg(带MSG_PEEK标志)。
以下示例是没有触发竞争,没有UAF的情况:
| 线程 0 | 线程 1 | 线程 2 |
|---|---|---|
| 调用 unix_gc | ||
| Stage0:将$f0_0$、$f0_1$、$f1_0$、$f1_1$、$f3_1$、𝛼列为垃圾候选 | ||
| $f2_1$调用recvmsg(带MSG_PEEK标志) ,获得$f1_1$’ | ||
增加引用计数:scm.fp = scm_fp_dup( UNIXCB (skb).fp) | ||
| Stage0:减少每个垃圾候选的飞行计数 | ||
| Stage0 之后的状态: inflight($f0_0$) = 0 inflight($f0_1$) = 0 inflight($f1_0$) = 0 inflight($f1_1$) = 1 inflight($f3_1$) = 0 inflight(𝛼) = 0 | ||
| Stage1:如果候选仍有飞行计数,则递归地恢复其飞行计数 | ||
| Stage1:所有飞行计数都已恢复完毕 | ||
| Stage2:没有垃圾,返回 | ||
| $f1_1$调用recvmsg(带MSG_PEEK标志),获得$f1_0$’ | ||
| $f1_1$调用recvmsg(不带MSG_PEEK标志),获得$f1_0$’’ | ||
| $f1_0$’调用recvmsg(带有MSG_PEEK 标志) |
但是,如果第2次调用recvmsg 发生在垃圾回收过程的Stage1之后,则会触发 UAF:
| 线程 0 | 线程 1 | 线程 2 |
|---|---|---|
| 调用 unix_gc | ||
| Stage0:将$f0_0$、$f0_1$、$f1_0$、$f1_1$、$f3_1$、𝛼列为垃圾候选 | ||
| $f2_1$调用recvmsg(带MSG_PEEK标志) ,获得$f1_1$’ | ||
增加引用计数:scm.fp = scm_fp_dup( UNIXCB (skb).fp) | ||
| Stage0:减少每个垃圾候选的飞行计数 | ||
| Stage0 之后的状态: inflight($f0_0$) = 0 inflight($f0_1$) = 0 inflight($f1_0$) = 0 inflight($f1_1$) = 1 inflight($f3_1$) = 0 inflight(𝛼) = 0 | ||
| Stage1:如果候选仍有飞行计数,则递归地恢复其飞行计数 | ||
| $f1_1$调用recvmsg(带MSG_PEEK标志),获得$f1_0$’ | ||
| $f1_1$调用recvmsg(不带MSG_PEEK标志),获得$f1_0$’’ | ||
unix_detach_fds() : UNIXCB (skb).fp = NULL 清空$f1_1$的接收队列 | ||
spin_lock(&unix_gc_lock) 阻塞 | ||
Stage1:scan_inflight() 无法从$f1_1$ 的接收队列中找到候选socket,无法恢复飞行计数。因此,飞行计数意外地保持不变。飞行计数等于0则不会将其从gc_candidates列表中移除,gc_candidates列表中都会被当作垃圾。 | ||
| Stage2: $f0_0$, $f0_1$, $f1_0$, $f3_1$, 𝛼 是垃圾。 | ||
| Stage2:开始清除垃圾。 | ||
| $f1_0$’调用recvmsg(带有MSG_PEEK 标志),预计会收到 $f0_0$’ | ||
获得 skb = skb_peek(&sk->sk_receive_queue),skb 将被线程 0 释放。 | ||
| Stage2:对于$f10 \rightarrow \begin{bmatrix} \sum{0}^N f0_0 \end{bmatrix} \rightarrow f1_0$,稍后调用 __skb_unlink() 和 kfree_skb() | ||
state->recv_actor(skb, skip, chunk, state) UAF | ||
| GC 完成 | ||
| 开始垃圾回收 | ||
| 获取 $f1_0$’’ |
因此,竞争会导致 skb 对象的 UAF。乍一看,问题在于第2次调用recvmsg 时清空了skb.fp,也即传递的文件列表。 但如果第1次调用 recvmsg 时没有设置 MSG_PEEK 标志,就可以避免 UAF,因为 unix_notinflight() 是通过垃圾回收序列化的。内核应当引入正确的同步机制,在减少飞行计数和删除 skb 之前必须确保没有正在处理的垃圾回收过程。这样在 unix_notinflight() 之后,receiver 获得 $f1_1$’ 并且飞行socket不会形成不可破的循环。
由于 MSG_PEEK 未通过垃圾回收进行序列化,因此当调用recvmsg(带MSG_PEEK标志)时 ,内核仍将 $f1_1$ 视为垃圾候选对象,这样下一次调用 recvmsg 时会因为垃圾回收过程的状态不一致而触发该漏洞。
3. 补丁分析
漏洞发现:在2016年就有研究人员将该漏洞报给内核社区(参见链接),并给出正确的补丁建议,但未被 Linux 内核社区接受。
Linux 内核开发人员:为什么我要应用一个 RFC 补丁,没有正确的提交消息,没有正确的签署,也没有来自其他知识渊博的开发人员的 ACK 和反馈?
2021年官方补丁:参见CVE-2021-0920的官方patch。对于 MSG_PEEK 分支,在执行敏感操作之前请求垃圾回收锁 unix_gc_lock 并且用完后立即释放。软件开发中很少见到这样的锁用法。
--- a/net/unix/af_unix.c
+++ b/net/unix/af_unix.c
@@ -1507,6 +1507,53 @@ out:
return err;
}
+static void unix_peek_fds(struct scm_cookie *scm, struct sk_buff *skb)
+{
+ scm->fp = scm_fp_dup(UNIXCB(skb).fp);
+
+ spin_lock(&unix_gc_lock);
+ spin_unlock(&unix_gc_lock);
+}
+
static int unix_scm_to_skb(struct scm_cookie *scm, struct sk_buff *skb, bool send_fds)
{
int err = 0;
@@ -2140,7 +2187,7 @@ static int unix_dgram_recvmsg(struct soc
sk_peek_offset_fwd(sk, size);
if (UNIXCB(skb).fp)
- scm.fp = scm_fp_dup(UNIXCB(skb).fp);
+ unix_peek_fds(&scm, skb);
}
err = (flags & MSG_TRUNC) ? skb->len - skip : size;
@@ -2385,7 +2432,7 @@ unlock:
/* It is questionable, see note in unix_dgram_recvmsg.
*/
if (UNIXCB(skb).fp)
- scm.fp = scm_fp_dup(UNIXCB(skb).fp);
+ unix_peek_fds(&scm, skb);
sk_peek_offset_fwd(sk, chunk);
BUG_ON 2017补丁:来自 Google 的 Andrey Ulanov 于 2017 年在unix_gc中发现了另一个漏洞并提交了patch。此外,该补丁还为飞行计数添加了BUG_ON()。
乍一看,似乎 BUG_ON() 可以阻止 CVE- 2021-0920 被利用。但是,如果通过制造大量假垃圾来延迟垃圾回收,利用堆喷射来避免 BUG_ON() 检查。
diff --git a/net/unix/garbage.c b/net/unix/garbage.c
index 6a0d48525fcf..c36757e72844 100644
--- a/net/unix/garbage.c
+++ b/net/unix/garbage.c
@@ -146,6 +146,7 @@ void unix_notinflight(struct user_struct *user, struct file *fp)
if (s) {
struct unix_sock *u = unix_sk(s);
+ BUG_ON(!atomic_long_read(&u->inflight));
BUG_ON(list_empty(&u->link));
if (atomic_long_dec_and_test(&u->inflight))
CVE-2021-4083:在作者与 Jann Horn 和 Ben Hawkes讨论CVE-2021-0920 时,Jann 在垃圾回收中发现了另一个漏洞,参见 Racing against the clock – hitting a tiny kernel race window。
参考
The quantum state of Linux kernel garbage collection CVE-2021-0920 (Part I)
CVE-2021-0920: Android sk_buff use-after-free in Linux
io_uring, SCM_RIGHTS, and reference-count cycles
文档信息
- 本文作者:bsauce
- 本文链接:https://bsauce.github.io/2023/05/10/CVE-2021-0920/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)