【bsauce读论文】2023-USENIX-AlphaEXP:识别Linux内核中的可利用对象
基本信息
- 原文标题:AlphaEXP: An Expert System for Identifying Security-Sensitive Kernel Objects
- 原文作者:Ruipeng Wang, Kaixiang Chen, Chao Zhang, Zulie Pan, Qianyu Li, Siliang Qin, Shenglin Xu, Min Zhang, Yang Li
- 作者单位:National University of Defense Technology, Tsinghua University
- 关键词:Linux内核, 漏洞可利用性, 自动化评估, AlphaEXP
- 原文链接:https://www.usenix.org/conference/usenixsecurity23/presentation/wang-ruipeng
- 开源代码:
1. 论文要点
论文简介:本文提出AlphaEXP(基于KINT [48], Syzkaller [19], Soufflé [28]实现),首先构造知识图谱来表示内核对象、内核功能和用户输入的关系,然后根据给定漏洞探索可能的攻击路径,标记可利用的对象,最后评估攻击路径的可行性,并对可利用的对象进行分类。
实验:对84个人工构造的漏洞和19个真实CVE进行测试,成功对大部分漏洞生成了攻击路径,找到50个对象可用于构造写原语,81个对象可用于构造读原语,112个对象可构造控制流劫持,并将这些对象分为12个等级。
2. 背景
2-1. 案例分析
漏洞点:第13行,当用户可控的skey->keylen (第11行)超过缓冲区skey->key的长度(该缓冲区的分配大小也由用户决定,第9行),就会触发OOB溢出。
漏洞利用:见图 (d),先构造漏洞对象tipc_aead_key和msg_msg相邻,溢出篡改 msg_msg->m_ts,构造越界读来泄露tty_struct结构的函数地址和堆地址;然后构造漏洞对象tipc_aead_key和tty_struct相邻,溢出篡改tty_struct->ops劫持控制流。
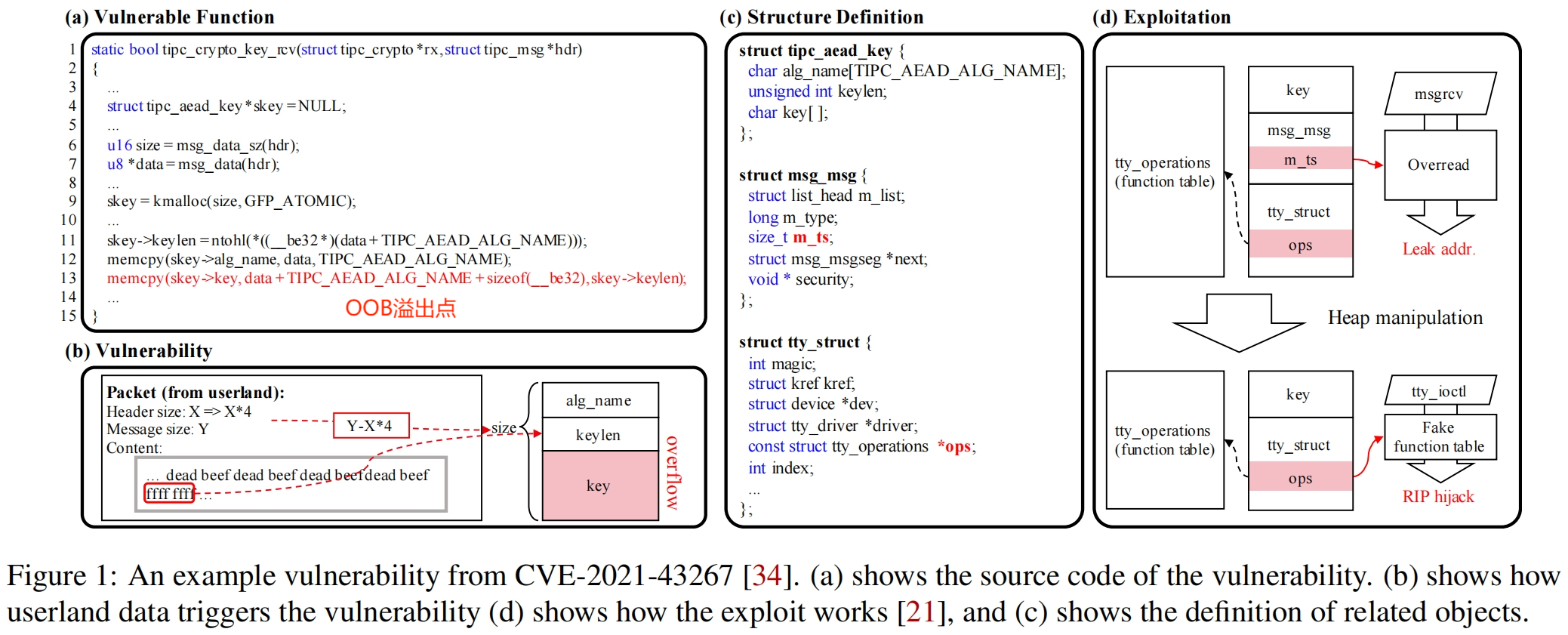
挑战:如何识别出类似msg_msg和tty_struct这些可利用对象并分类。
2-2. 漏洞利用步骤
利用过程分为两个阶段,Capability Upgrade (CU) 和 Capability Stitching (CS)。首先将初始的漏洞能力转化为更强的能力,最常见的有两种,一是读能力和任意代码执行(ACE),二是读能力和任意地址写(AAW),可以绕过KASLR并提权。然后将多种能力组合起来,实现提权。
3. AlphaEXP
威胁模型:开启SMEP, SMAP [14], KPTI [15], KASLR [17]。只生成攻击路径,而非EXP,不考虑堆布局技术。
AlphaEXP整体架构:包含三个部分,知识图谱构建(收集内核对象信息),攻击路径生成(推断哪些对象可以用于利用),可利用对象分类(根据利用条件和能力的影响)。
实现:知识图谱构建是基于 KINT[48] 和 Syzkaller;攻击路径生成是基于Soufflé [28]。
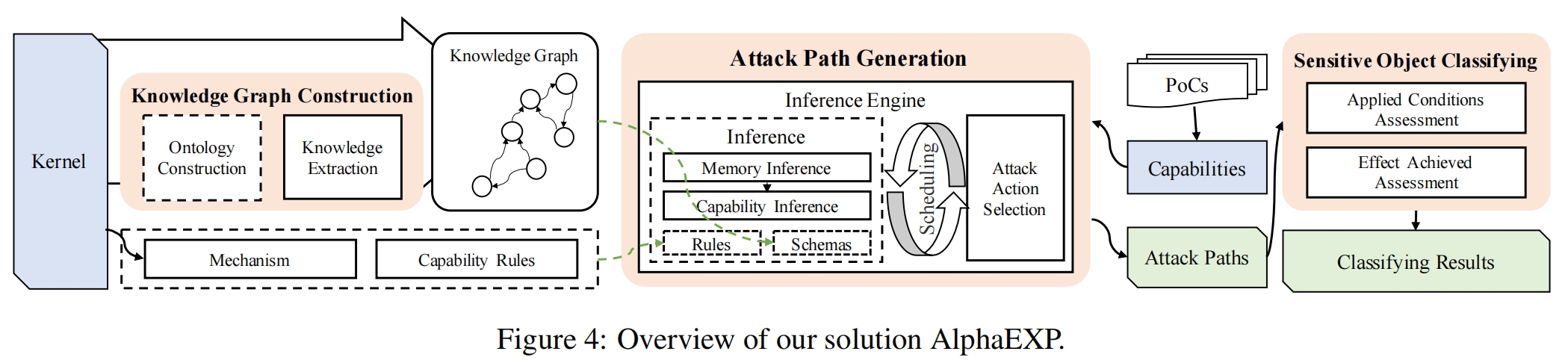
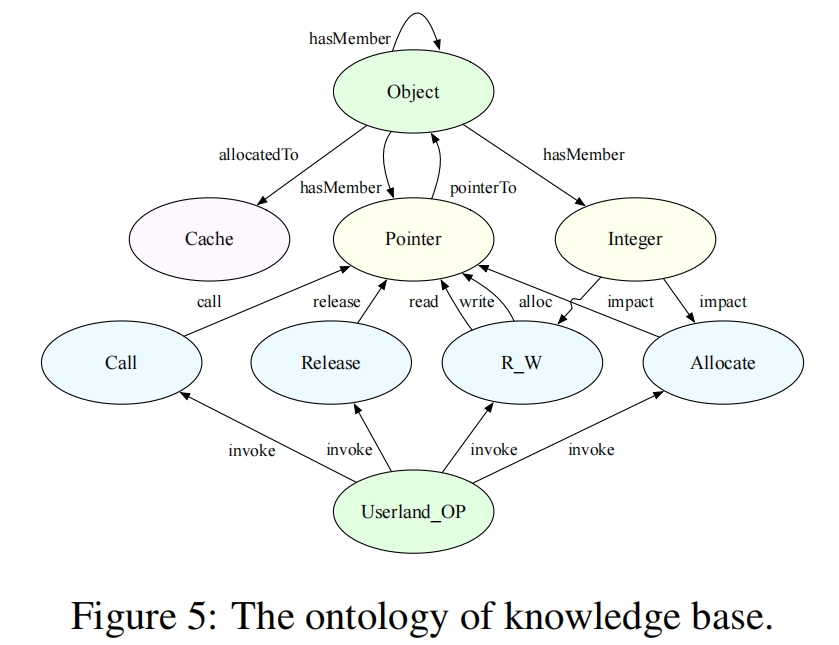
3-1. 知识图谱构建
目标:能反映内核对象、内核功能和输入的关系。
组成:
- object信息:包含位置信息和成员信息。
- 位置信息:所属Cache;
- 成员信息:Pointer(可作为释放函数的参数)、Integer(可作为分配函数的参数)。
- 内核功能:
- R_W / Call:读/写和对敏感对象执行常见操作,有利于利用;
- Release / Allocate:有利于利用。
- 用户操作:能触发相应内核功能的用户操作。
静态知识收集:LLVM静态分析,收集对象和内核功能函数的关系。先收集内核对象的结构和size;再收集内核功能,例如copy_from_user(), copy_to_user(), kmalloc(), kfree(),对应读/写/分配/释放;最后识别哪些对象的成员会影响内核功能函数的参数,数据流分析 use-def链。同时,还识别间接调用,例如call i64 %1(i8* %2, i8* %2)的函数指针是否来自某个对象,有利于控制流劫持。
动态知识收集:fuzz技术,识别用户操作如何触发内核功能函数。先在内核功能函数处插桩,然后采用fuzz生成能触发内核功能的测试用例。
3-2. 攻击路径生成
(1)攻击动作选择:选取用户操作。首先是随机选取一个,但是遵循两个原则,一是考虑对象所属的kmem-cache是否合适,二是已具备的能力(例如已具备任意读)就不再选取。
(2)推断:推断用户操作的有效性。基于Datalog[8]进行自动推断。模式和规则参见Table 1。
- 模式:3种
- 知识图:来自知识图谱,例如对象所属cache。
- 内存状态:用于推断用户操作导致的内存状态,重点关注指针和内存的关系(例如
PointTo/PointerType/PointerStatus)。注意,DestroyPointer用于区分不同的内存释放方式,确定是否有漏洞。 - 非预期能力:根据当前状态推断是否具备非预期能力(读/写/执行)。
- 规则:2种
- 内存:基于内核内存分配,有助于推断攻击路径。
- 能力:基于利用经验。例如,如果具备写功能的指针被污染,则可以构造任意地址写。

(3)调度:确定推断结果是否符合预期,确定攻击动作是否加入到攻击路径。经过前面两步分析,已经生成了攻击子路径,接下来需不断评估子路径,直到找到能够生成利用的路径。
3-3. 可利用对象分类
分类:根据利用条件和利用影响进行分类。
- 利用条件:主要看三个因素,重要度由高到低。
- 一是所属kmem-cache,有的对象大小固定(例如
sembuf),有的对象分配大小用户可控(例如drm_property_blob)可用于不同大小的漏洞对象; - 二是所需入口能力,例如,利用
tty_struct对象需覆写其第41个成员,而利用seq_operations对象则只需覆写其第1个成员; - 三是所适用漏洞类型,例如,
setxattr()函数的分配和写入是连续的,不适用于OOB,只适用于UAF。
- 一是所属kmem-cache,有的对象大小固定(例如
- 利用影响:读 / 写 / 执行能力。写能力最重要,执行能力次之,最后是读能力。例如,
msg_msg同时具备读/写能力,所以利用影响更大。
4. 实验
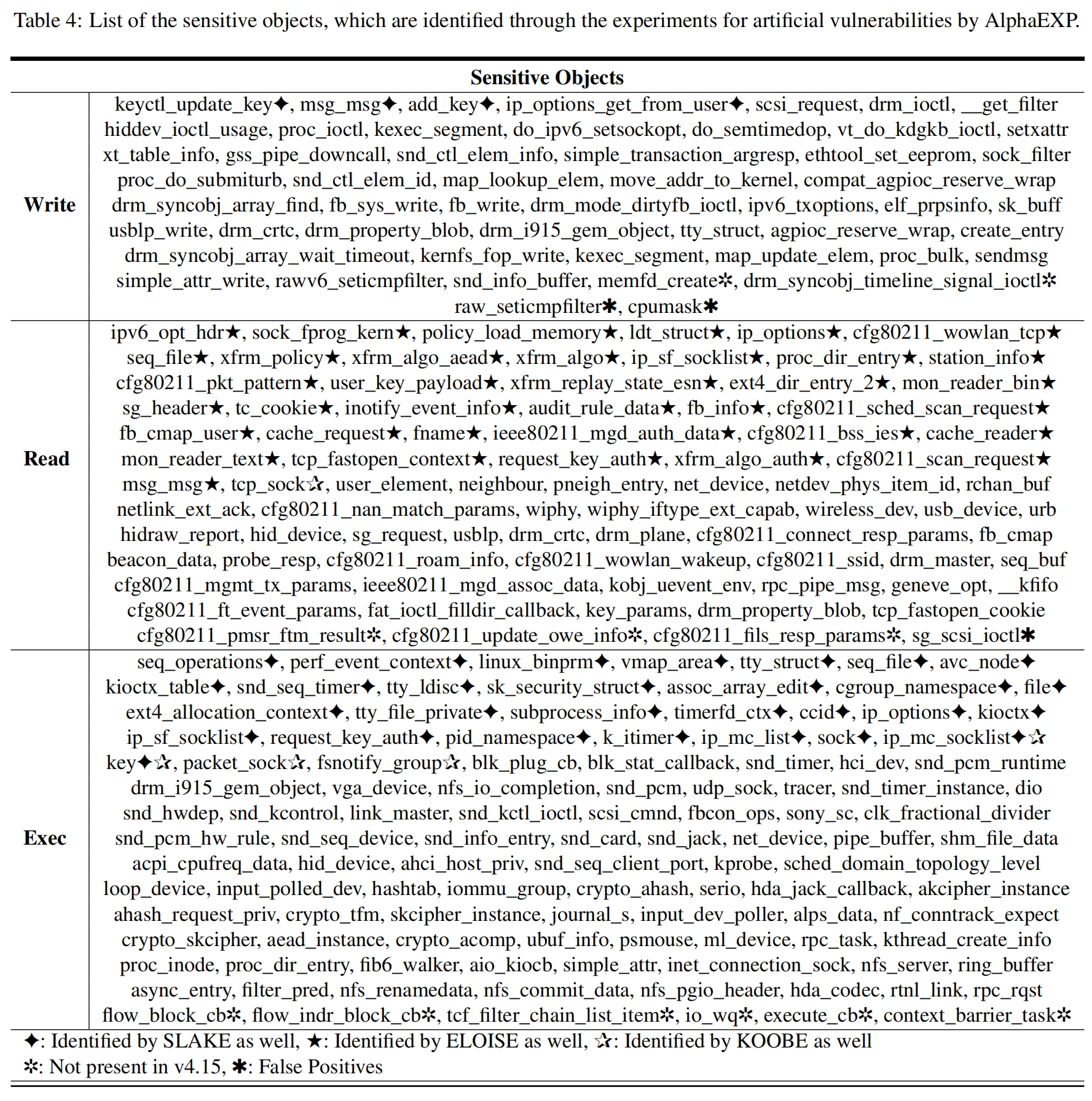
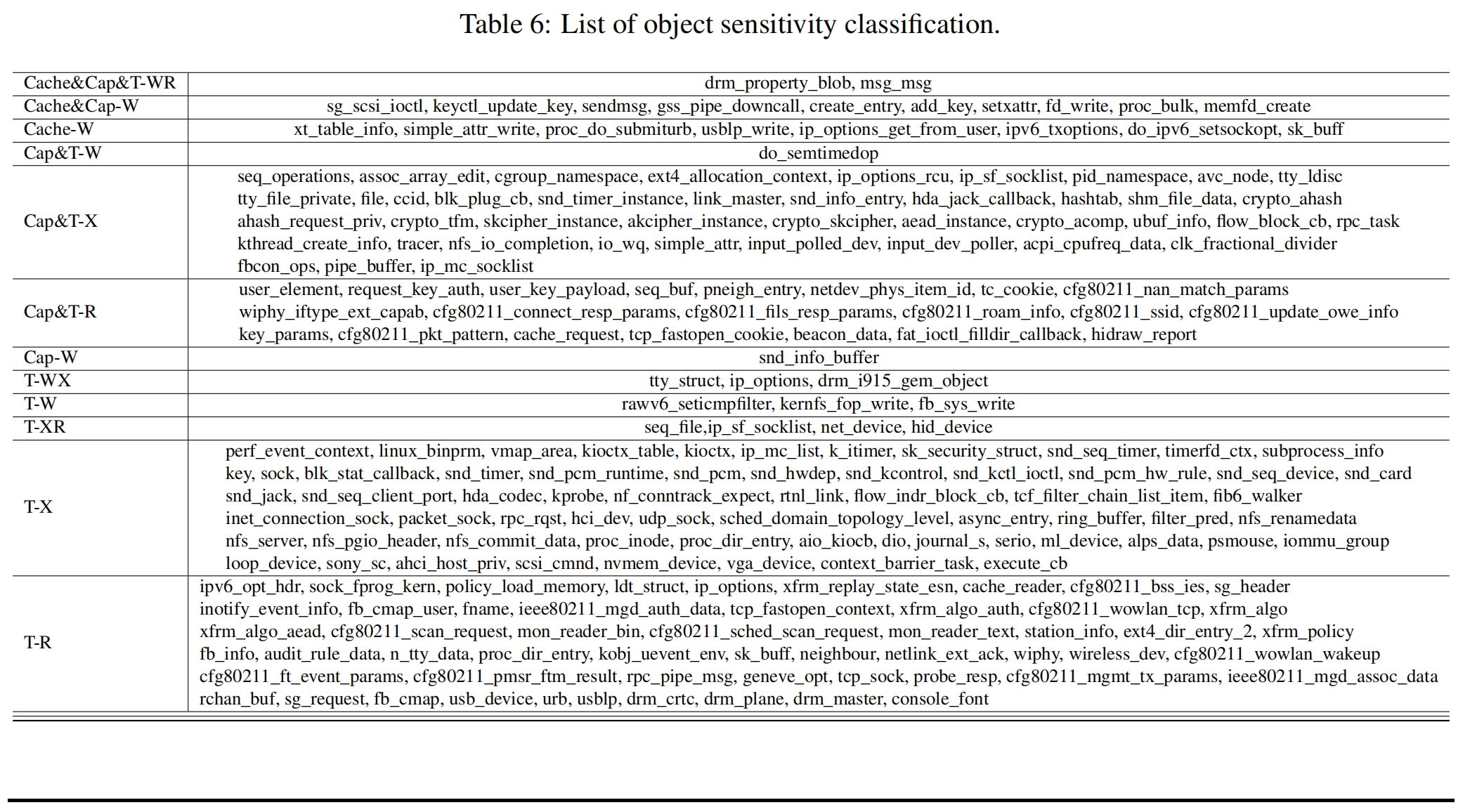
实验结果:可利用对象识别与分类。识别出50个对象可用于构造写原语,81个对象可用于构造读原语,112个对象可构造控制流劫持,并将这些对象分为12个等级。12个等级是根据利用条件(Cache / 入口能力-Cap / 漏洞类型-T)和利用影响(W / R / 执行-X 能力)的组合来决定,例如,Cache&Cap&T-WR 表示该对象对cache、入口能力和漏洞类型没有要求,非预期能力是读/写。详细分类结果参见Table 6。
文档信息
- 本文作者:bsauce
- 本文链接:https://bsauce.github.io/2024/05/22/AlphaEXP/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)