扩展学习:lockset分析、happens-before分析。
摘要
Data race:两线程访问共享数据时未使用正确的同步。
原因:以往的fuzzer聚焦于单线程,无法发现并发漏洞,如数据竞争。
解决:KRACE—端到端fuzz框架,改进覆盖引导型fuzzing来挖掘并发漏洞。a.新的覆盖追踪度量标准,别名覆盖;b.新的算法,生成/变异/合成多线程syscall序列;c.对内核同步原语进行全面的lockset和happens-before分析,以准确检测data race。
实验:在ext4、btrfs文件系统中发现23个data race,其中9个有害,11个良性。
1.Introduction
背景:并发漏洞危害很大,检测难度也大。开发者一般通过压力测试来检测并发漏洞,但文件系统越来越复杂。目前已有内核fuzzer可以对文件系统进行fuzz,如Hydra[6]针对文件系统的语义漏洞,Razzer[24]针对竞争漏洞。已有的覆盖引导型fuzz中的分支覆盖不足以反映线程的交错情况(不同的线程交错可能有同样的分支覆盖);同时也无法合成多线程程序,无法增大线程交错。
KRACE创新点:
(1)覆盖率追踪:分支覆盖+别名指令对覆盖
别名覆盖,收集可能引发线程交错的内存访问指令对X↔ Y,执行时记录覆盖了多少交错点,若覆盖不再增长,则fuzzer停止探索当前种子。
(2)输入生成:变异/整合多线程种子+线程调度
由于内核有太多复杂的背景线程,不适合对全内核调度,所以采用轻型的延迟注入,来间接调度。
(3)漏洞检查:给定执行trace,离线检查是否data race
hook所有内存访问,若有一对访问同一地址,且满足,a.位于不同线程,一条是写;b.有顺序性,满足happens-before关系;c.至少有一种共享锁保护该访问(lockset分析)。
难点:
- 需要对不同的内核同步机制建模,如乐观锁、RCU、ad-hoc定制锁。
aging problem问题,每次执行需从干净的内核状态和空文件系统镜像开始。data race检查速度慢,只有在产生新覆盖(分支+别名覆盖)时,才调用checker。
贡献:
- 提出别名覆盖的度量标准+交错多线程syscall序列合成,是fuzz并发漏洞的基础。
- 实现
data race checker,对内核同步机制进行全面建模。 - 影响:KRACE发现23个
data race,并将一直fuzz下去。
2.背景和相关工作
(1)Example

漏洞分析:见Fig-1,btrfs中,有1读2写竞争访问full,但读访问没有对delayed_rsv->lock上锁(效率原因)。若执行顺序是1->2->3->4,则block_rsv_release会释放fsync将使用的字节,导致整数溢出。
识别data race关键:a.如何确定某执行会导致竞争;b.如何利用代码分析+线程调度 生成有意义的执行。
(2)动态data race检测算法
已有研究:
a.
happens-before分析[29]:有漏报。b.
lockset分析[30]:手动标注常见的lock/unlock函数,寻找原子性违例。c. [31,32]提出优化,[33,34]组合
happens-before与lockset分析
存在问题:
- a.
happens-before和lockset只针对部分同步原语。解决:KRACE也是组合happens-before和lockset分析,不仅分析保守锁(eg, mutex / readers-writer / spinlock),也分析乐观锁(sequence lock / RCU / publisher-subscriber models)。 - b.
happens-before和lockset若标注不全,如漏掉某种锁导致误报。解决:一是timing-based detection,在线程访问内存时延迟一定时间,再检测访问冲突,缺点是需要精确控制线程执行速度,增大了搜索空间(在哪延迟、延迟多久);二是采用取样法sampling,降低追踪内存访问所需的运行时开销。
(3)代码路径探索/线程调度探索
代码路径探索:a.[7,36,37]手写测试用例,但不能处理复杂情况,如Fig1,用户线程需mkdir出和内核线程uuid_rescan相同的目录,手写很难触发此路径;b.最新OS fuzzer[5,6,21,27]根据syscall定义生成测试用例,但只能生成单线程程序,不能处理多线程程序。KRACE可处理多线程程序。
线程调度:a.随机调度[14];b.运行时加入延迟[13,36,37];c.枚举所有线程交错情况[7,24]。KRACE采用延迟注入。
(4)检测data race
KRACE参考了[7,24,45,46]四篇论文。
DataCollider[45]:对内存访问随机取样来分析,挖掘Windowss内核模块。
KCSan[46]:Syzkaller[21]的Kernel Concurrent Samitizer[46],编译时插桩插上软件断点,利用happens-before分析检测非原子性访问。
SKI[7]:采用PCT算法[48]和硬件断点来列出线程调度情况。缺点是只针对用户线程,没管内核背景线程,且线程排列方案过于简单,会漏报。
Razzer[24]:结合静态分析+fuzz。首先对全内核指针分析,以找到别名对;再生成能执行别名指令的syscall序列;再将单线程syscall序列转化为多线程程序,探索data race。缺点是:a.指针分析产生的别名对太多,无法一一分析;b.且不明确如何生成执行别名指令的syscall。
KRACE重点是提高别名指令对的覆盖率,和RAZZER利用指针分析提前确定搜索空间不同,KRACE利用覆盖引导型fuzzer和边覆盖bitmap增大并发搜索,不需要求解能到达指定点的syscall和相应参数。
(5)fuzzing
用户空间[16,20,50-54]/内核空间[5,6,21,22,27,55]只针对内存破坏漏洞、单线程程序。Moonshine[25]捕捉syscall之间的依赖关系;DIFUZE[26]可生成interface-aware输入。但由于缺乏针对并发的覆盖率度量方法+多线程种子进化算法,很难fuzz出内核data race漏洞。
(6)对内核进行静态和符号化分析
静态lockset分析[40-44]挖掘并发漏洞,但由于缺乏happens-before关系,且指针分析有限制,导致误报率高。
静态分析对内核驱动漏洞挖掘很有效。SymDrive[60]使用符号执行模拟设备并验证驱动特性;DrChecker[61]能发现8种安全漏洞。但不适用于挖掘文件系统,因为漏洞多发生于多个syscall的交互。
3.并发程序的覆盖率度量
3.1 分支覆盖
Example:见Fig.2,KRACE发现的一个data race,两线程执行symlink、readlink、truncate,当B==C时,两线程同时访问全局数组G,导致data race。
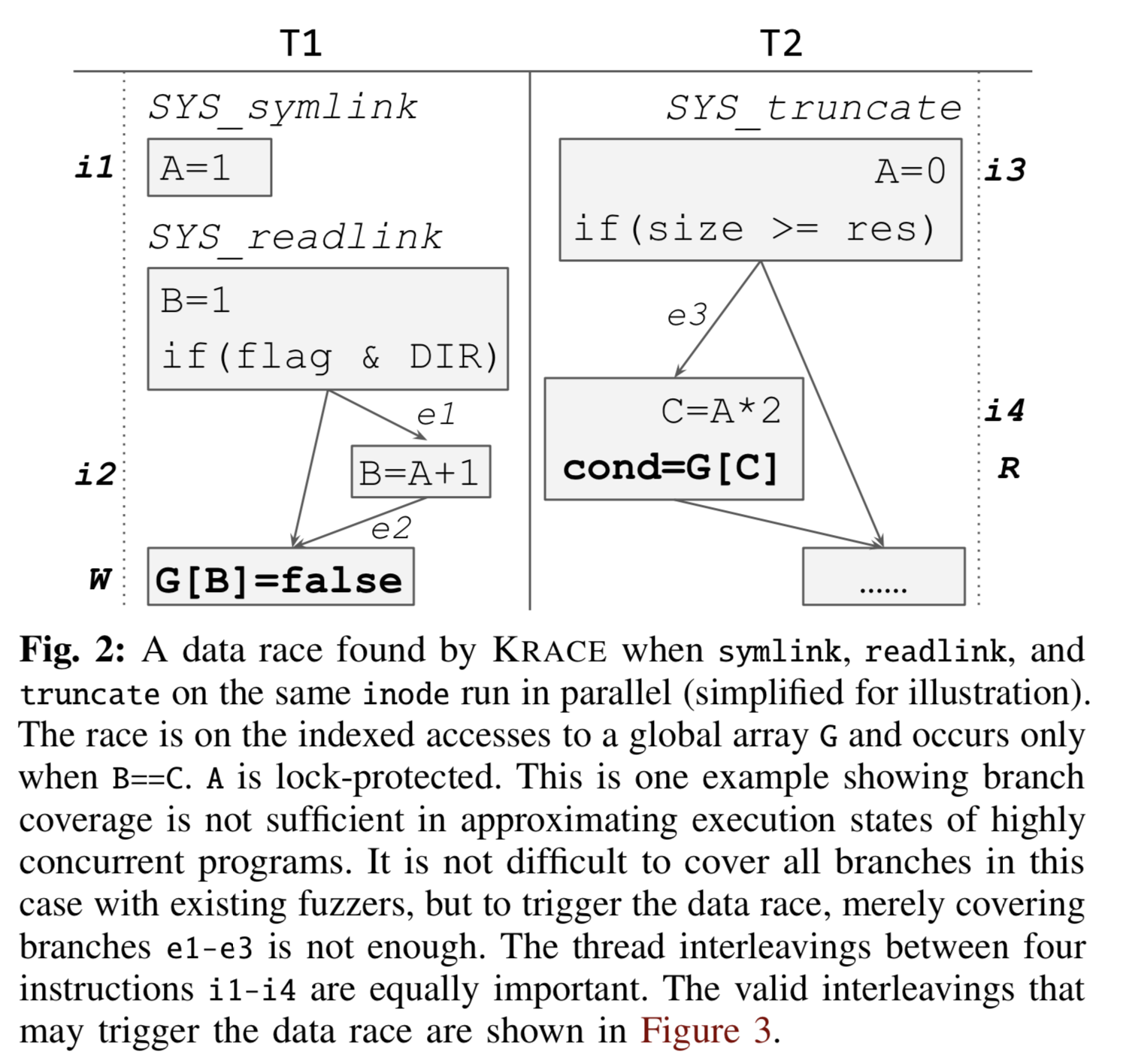
分支覆盖:覆盖e1/e2/e3分支很容易,但无法触发data race,无法触发i1-i4指令的交错执行。见Fig.3,6种交错情况的分支覆盖是一样的,只有5/6能触发data race。

3.2 别名覆盖
形式化定义:定义所有内存访问指令:i1,i2,… ,iN。A ← <ix, tx> 表示tx线程中ix指令往内存地址A写,若出现另一条写指令iy则更新为A ← <iy, ty> ;若处于同一线程tx == ty则不用更新;若iy是读指令,则用有向对ix→iy 表示一条别名覆盖。Eg,Fig-3中1/4没有定义-使用关系,2/3是i3→i2,5/6是i1→i4。
反馈机制:若别名覆盖持续增长,则在内存访问指令处注入更多延迟;若不增长,则探索其他种子。
覆盖敏感性微调:分支覆盖平衡的路径覆盖和基本块覆盖的有效性、速度、bitmap计数开销。别名覆盖若考虑敏感性,可灵活选取1st-order、2nd-order、Nth-order别名对,但并非本文研究点(本文发现63590个别名指令对,对应bitmap大小是128KB)。
4. 并发fuzzing的输入生成
4.1 多线程syscall序列
基于说明的syscall合成:基于说明来引导syscall参数的生成和变异,说明也表现了syscall之间的参数依赖关系(Eg,write依赖create返回值)。
种子格式:见Fig-5中Seed 1,一个syscall list含3个线程,分别是mkdir-close, mknod-open-close 和 dup2-symlink。
进化策略:变异、添加、删除、洗牌打乱,见Fig-4。
合成多线程种子:syscall相对顺序保持不变(保持syscall之间的依赖关系),交织合成。见Fig-5。
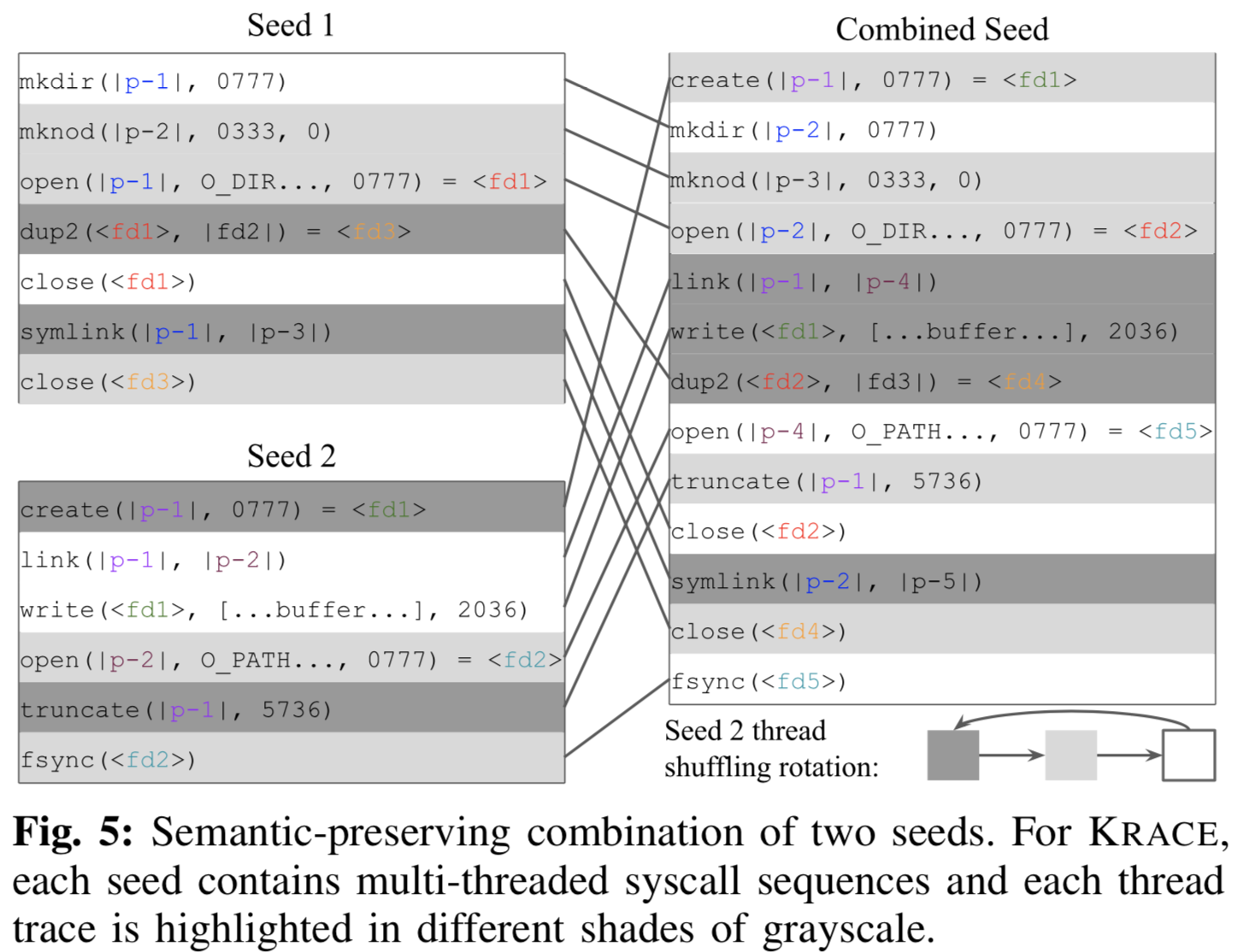
原语收集:首先对种子剪枝,只留下成功执行的syscall;再分成多个原语,原语内部的syscall之间互相依赖。作者在68个FS中提炼出10000个原语。
4.2 线程调度
运行时延迟注入:用一段缓冲区存放随机数,在每个内存访问点取1个随机数T,延迟T时间。注入点可选在基本块或函数级,以免过于细粒度带来开销。见Figure 6。
5.Data race检测
5.1 data race检测步骤
data race候选指令对
- 访问同一内存地址
- 指令位于不同上下文tx、ty
- 其中一条指令是写
data race分析过程:若指令对满足以下两点则为data race
- ix、iy没有同时占有锁(
lockset分析) - ix、iy执行顺序不固定(
happens-before分析)
说明:lockset分析需要弄清所有的上锁机制,happens-before分析需要标注所有的顺序原语,否则会有误报。
5.2 lockset分析
(1) lockset分析
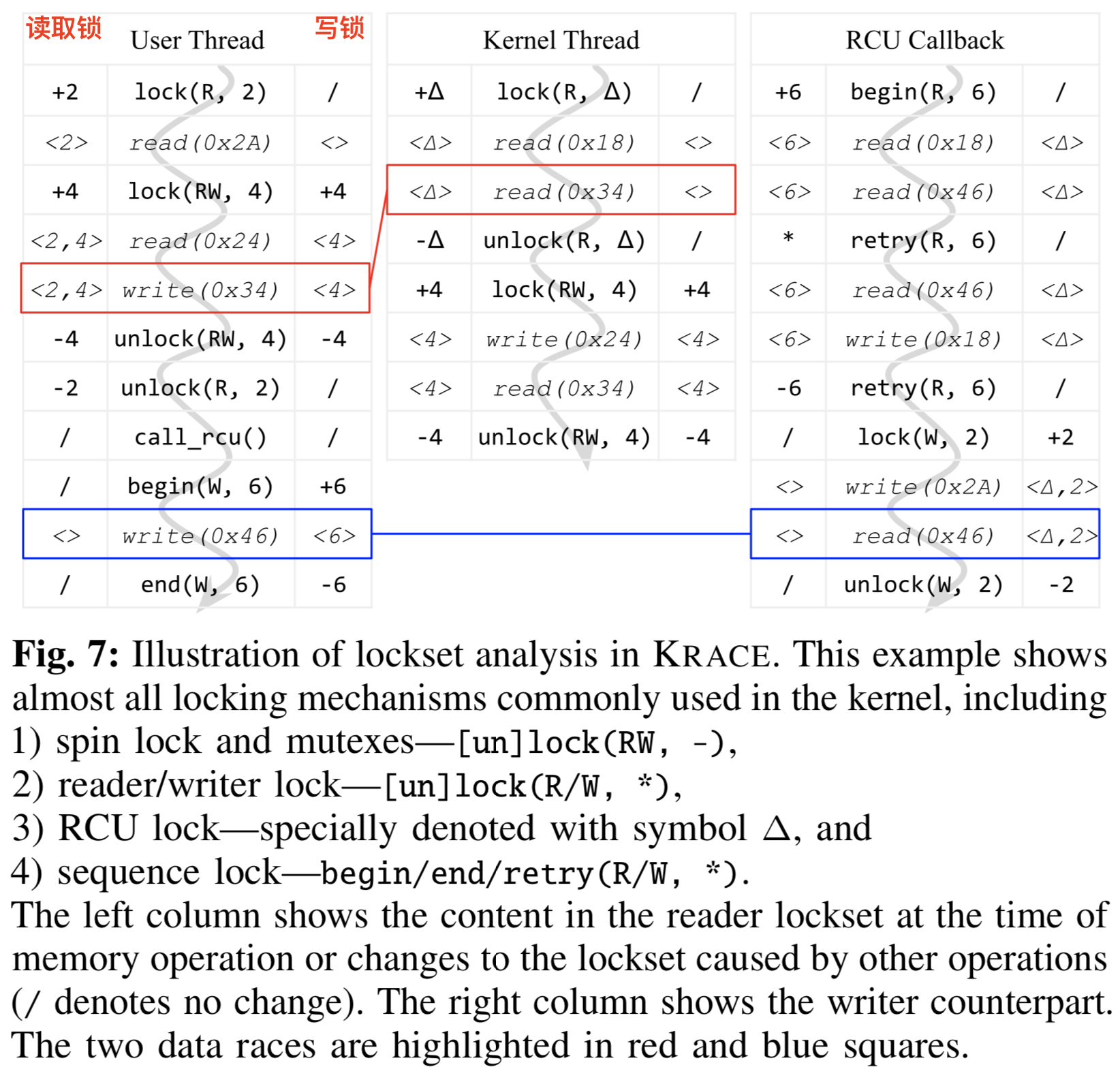
锁特性:读取锁可被多个线程同时获取,写锁只能被1个线程获取。
标记:LS^R^ ~<t,i>~ ——线程t在指令i处的读取锁;LS^W^ ~<t,i>~ ——线程t在指令i处的写锁。
lockset分析:只要竞争指令对<tx,ix>和<ty,iy>不满足以下情况,表示两指令没有用同一种锁,则tx和ty可以任意交错执行,则是真的data race。
- LS^R^ ~<tx,ix>~ ∩ LS^W^ ~<ty,iy>~ != ∅
- LS^W^ ~<tx,ix>~ ∩ LS^R^ ~<ty,iy>~ != ∅
- LS^W^ ~<tx,ix>~ ∩ LS^W^ ~<ty,iy>~ != ∅
示例:见Fig-7,对0x34和0x46地址的读写(红框和蓝框),两处错误的读写都使用了不同的锁。
(2)保守式锁(pessimistic locking)
简介:获取锁时会一直等待该锁被释放,lock/unlock成对出现,如spin lock、reader/writer spin lock、mutex、bit locks、read/writer semaphore(信号量)。
特例:RCU机制,详细介绍见这里,RCU只对读取加锁(rcu_read_[un]lock),写不加锁,通过宽限期来实现。当__rcu_reclaim调度RCU回调函数,则保证了此时没有RCU读取锁,所以通过RCU回调函数来确定写操作lock/unlock位置。
(3)乐观锁(optimistic locking)
简介:无锁设计。如顺序锁sequence locks[66],乐观的任务读取某关键数据时,不会被修改。问题是关键数据的结尾不明确,可根据begin/retry表示开头和结尾。
5.3 Happens-before 分析
简介:happens-before分析目的是弄清线程执行的先后次序,比如线程A创建线程B,那么在创建点之前A和B不会有竞争。Eg,见Figure-8,i6必在i2之后执行(queue_work控制);i4和i8不会竞争,只有执行wake_up(c12→ c5)后,满足条件cond1才会执行i4。
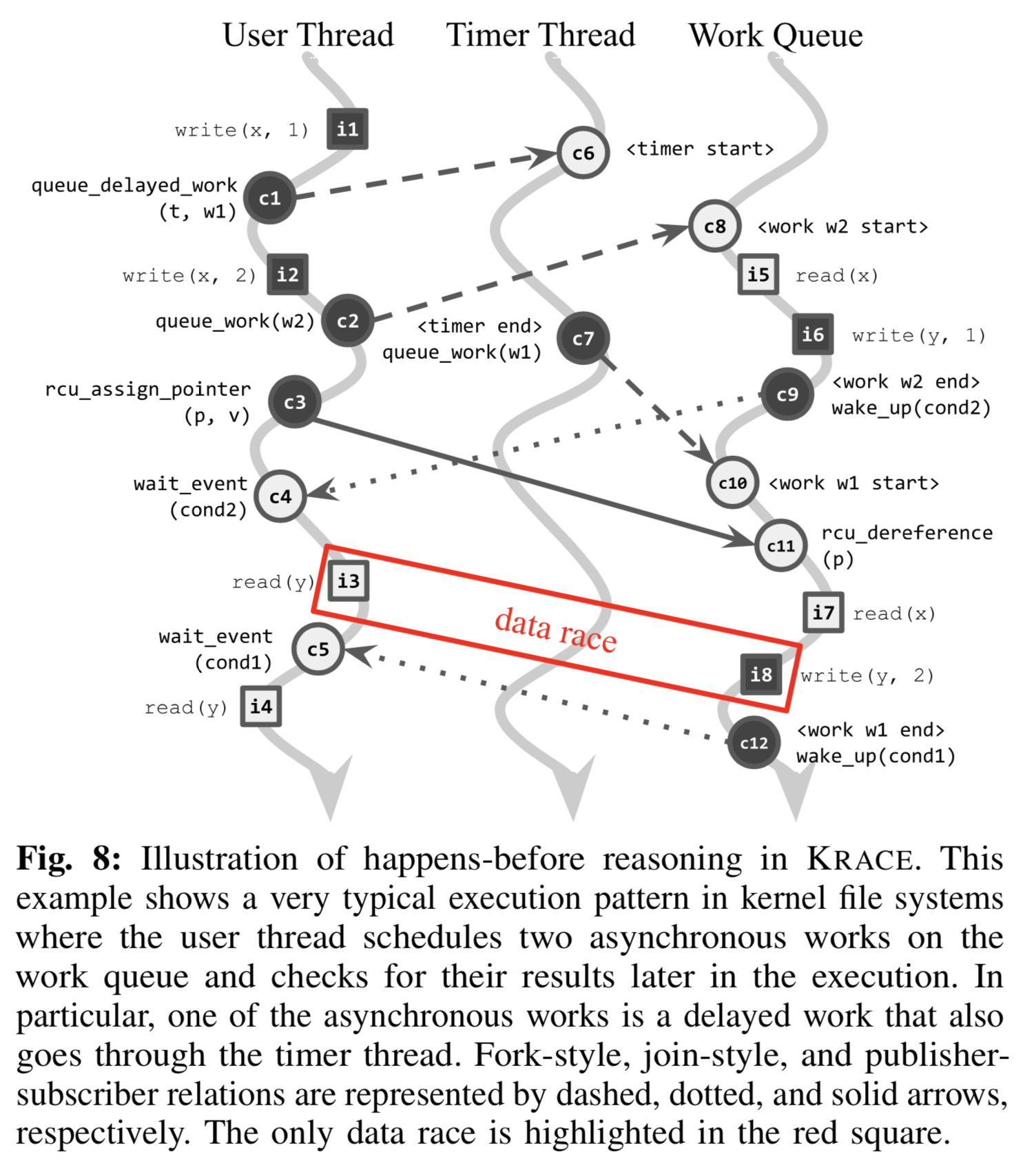
方法:hook内核同步API,形式化分析happens-before关系。见Figure-8,线程之间有一定顺序,形成一个有向非循环图,将<tx,ix>和<ty,iy>是否竞争问题转化为图可达问题。若存在X指向Y,则X必在Y之前执行,不可能竞争;若没有HB关系,则有竞争,如i3和i8指令。
HB类型:
- Fork-style(fork子线程/进程):如RCU回调、work queue、kthread-simulated 工作队列、directed kthread forking、timers、软件断点softirq、inter-processor interrupts (IPI)。hook这类API很容易。
- Join-style(等待类API):如
wait_event、wait_bit、wait_page。需同时hookwait调用和wake_up调用。 - Publisher-subscriber model(发布/订阅者模型):如RCU指针赋值与引用[35],例如用户线程从RCU保护的
fdtable文件描述符fd,fd必须是之前发布过的。所以对象的allocate-and-use模式就是:发布者线程分配一个内存对象,初始化后将该指针插入到全局或堆数据结构(通常未list或哈希表),订阅者线程之后会使用该对象。KRACE可追踪内存分配API、监控该分配指针何时首次被放进公共内存、及何时被再次使用。
6.KRACE总览
6.1 架构
总体架构见Fig-9,第一步Compile-time preparation是为了插桩,便于动态运行时搜集别名/分支覆盖,动态运行时还需要利用hook API收集用于判断data race的信息;第二步Fuzzing loop功能就是fuzz,多了处理多线程种子的能力。
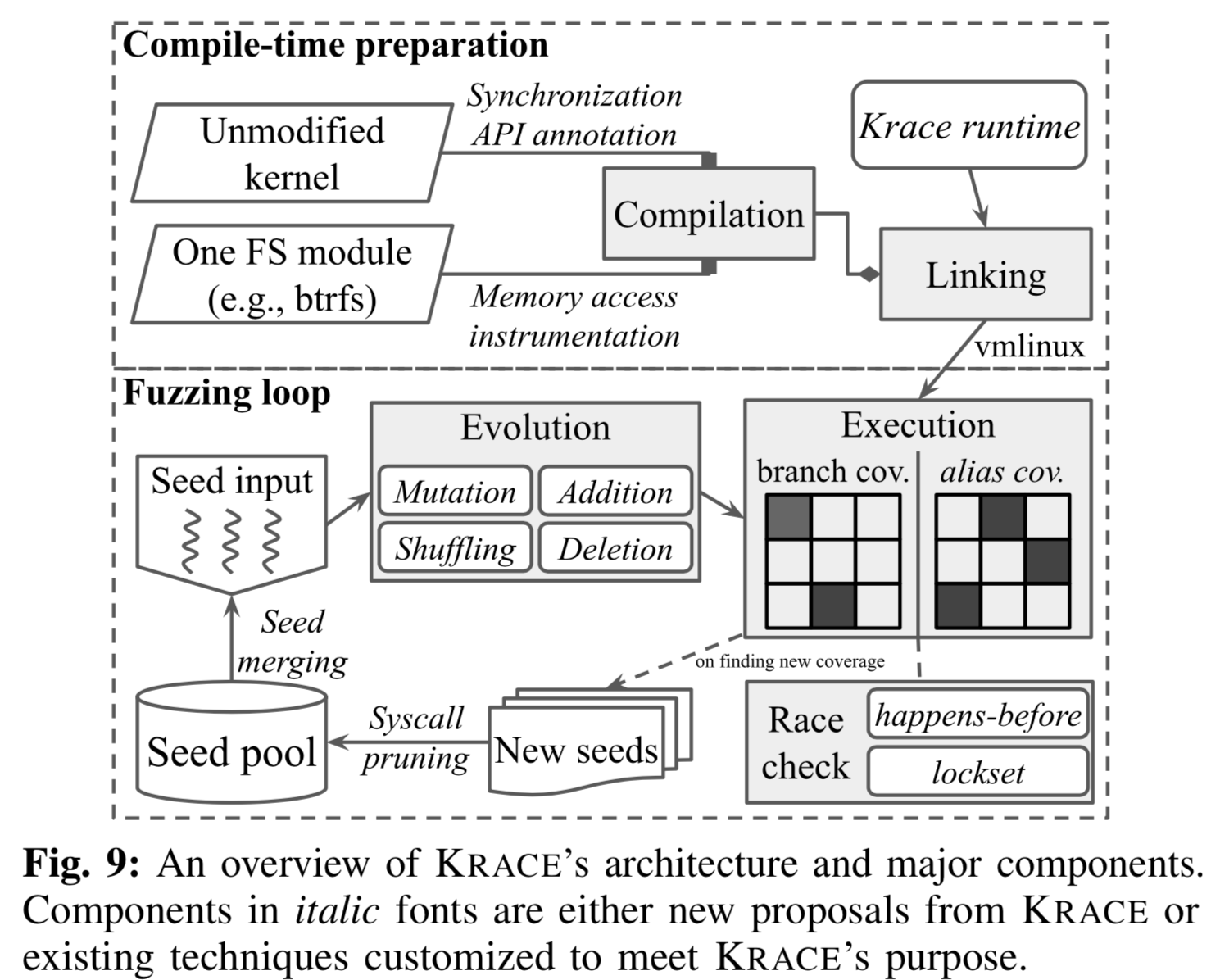
(1)代码插桩
对FS相关模块(目标FS、虚拟文件系统层VFS、日志模块jbd2-ext4)的访存指令插桩;标注出lock/unlock、顺序原语(影响HB关系)对应的API。
(2)Fuzzing loop
见Fig-15。步骤:
- 1.整合已有种子,生成新program(种子选取:选较少使用的)
- 2.扩展program:添加/删减syscall
- 3.修改program:变异syscall参数
- 4.多次运行,插入不同的延迟
- 5.检查data race,剪枝并保存program为种子
可修改变量ext_limit、mod_limit、rep_limit,KRACE取值为10、10、5。若某一种子连续运行5次发现了新的分支/别名覆盖,则插入新的delay再运行5次;若连续5次运行没有发现新覆盖,则变异syscall参数或打乱syscall;若连续50次运行没发现新覆盖,则增减syscall;若连续500次运行没发现新覆盖,则整合2个种子生成新种子。

(3)离线data race检查
只要发现新的分支/别名覆盖,则有其他线程离线检查执行log。
6.2 良性/恶性 data race
良性竞争:a. statistics accounting:如__part_stat_add ,这些数据只是信息或提示,不保证准确性;b.读写同一变量的不同字节:2-/4-/8-byte,如bit-flags,如inode->i_flag 或文件系统控制结构的flags fs_info。
区分良性竞争方法(不准确):a.变量名含stat或位于statistics accounting函数;b.对同一变量的不同bit读写;c.某些可容忍竞争的内核函数,如list_empty_careful 。
6.3 aging OS问题
问题:如果fuzz时始终不重启系统,某些漏洞可能是积累产生的,搞不清漏洞的原因。
解决:每次fuzzing时用新的内核和干净的文件镜像。Janus[5]利用LKL[68]来快速重载,但是LKL不支持SMP架构(SMP是多线程的前提)。
6.4 讨论&限制
(1)确定性重放
KRACE不能准确重放某次执行。
(2)可调试性
KRACE可生成全面的data race报告:这样开发者不需要重放就能判断良性/恶性。
- a.竞争点:定位到源码中对应的行数。
- b.调用路径:根据基本块分支信息,恢复调用路径(含syscall入口点或线程创建点)。
- c.回调图:根据
happens-before分析得到callback图。
(3)漏报
有些新的程序状态并不增加新的别名覆盖,如新的交错方式,KRACE为了效率直接不考虑这种情况,导致漏报。
6.5 实现
KRACE分为两部分,对应代码行数见Table3。一是编译时准备,包含内核源码标注(以patch形式)、LLVM插桩pass、KRACE内核运行时库(提供覆盖追踪和记录);二是基于VM的fuzzing loop,包含测试用例生成、在QEMU VM中执行、检查data race。runtime executor见Fig-10。
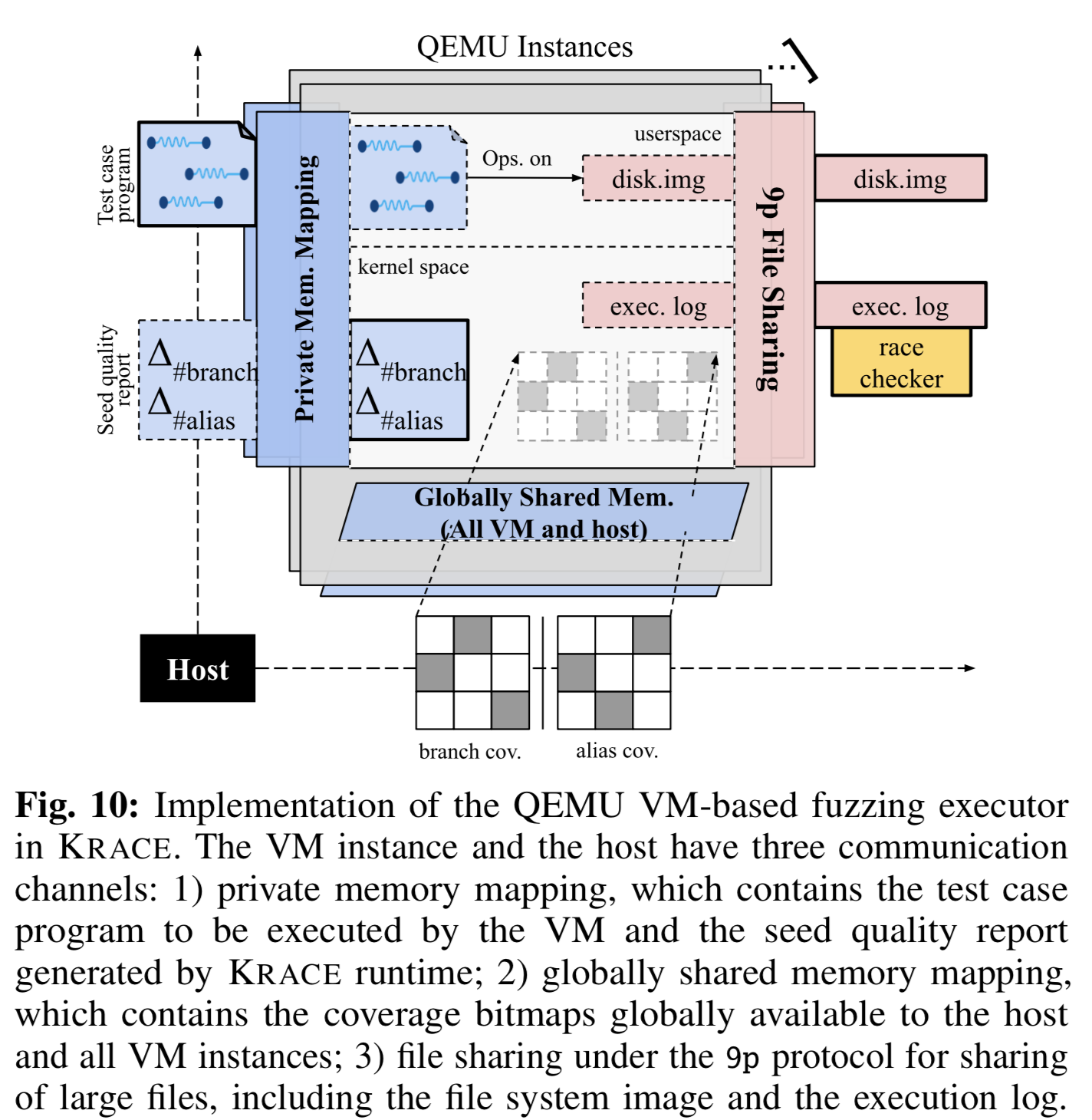
(1)Runtime executor
难点是host和VM-based fuzzing instance间的信息共享机制,用于种子注入、覆盖追踪、反馈搜集,有3种机制,private memory mapping (PCI memory bar), public memory mapping (ivshmem), the 9p file sharing protocols 。
(2)内核构建
内核版本v5.3,LLVM 9.0,编译最小内核(含block layer、loopback device、支持在QEMU/KVM执行和加速的驱动),FS以模块形式编译可灵活加载。
(3)Initramfs
不用busybox,init程序负责:1) starts tracing, 2) loads file system modules, 3) mounts the file system image, 4) interprets the program, 5) unmounts the file system image, 6) unloads the modules, and 7) stops tracing。
(4)覆盖追踪
插桩实现,桩上调用KRACE运行时库,如on_basic_block_enter、on_memory_read。KRACE可直接更新host内存区域中的coverage bitmaps(可被所有VM实例看到),每次更新都是一次test_and_set_bit 操作,由QEMU ivshmem保证其原子性。
(5)execution log
格式是[<event-type>, <thread-id>, <arg1>, <arg2>, ...] ,由KRACE运行时库来填充,用于data race检测和调用路径恢复。
7.实验
环境搭建:two-socket, 24- core machine running Fedora 29 with Intel Xeon E5-2687W (3.0GHz) and 256GB memory。性能评估是在Linux v5.4-rc5上做,fuzzer在v5.3上跑,文件系统是btrfs和ext4,文件系统镜像是通过mkfs.*创建,并行跑24个VM,每个VM跑3个线程种子。
(1)Data race数量
在btrfs和ext4中发现23个data race,9个有害,11个良性,剩余的仍在评估,结果见Table-1。
(2)fuzzing特性
覆盖增长:分支/别名覆盖见Fig-11(btrfs)、Fig-12(ext4)。覆盖大小方面,btrfs和ext4的分支覆盖相差不大,但btrfs的别名覆盖较大,因为btrfs背景线程多达22个,ext4只有1个;覆盖增长同步方面,分支/别名覆盖的增长是同步的。
插桩开销:执行的syscall越多,开销越大。
data race检测开销:检测开销取决于执行路径的长度。
(3)组件评估
覆盖有效性:发现别名覆盖(线程交错)有助于提高分支覆盖。原因是有助于突破一些锁检查。
延迟注入有效性:延迟注入有助于发现别名覆盖。
种子整合有效性:种子合成能保留syscall之间的语义,有助于发现别名覆盖。
data race检测组件:lockset分析(保守锁+乐观锁)、happens-before分析(fork-style+join-style+publisher-subscriber模型+自定义的方式)。
(4)比较其他fuzzer
执行速度vs覆盖:KRACE速度很慢,但是覆盖大小KRACE>Syzkaller。
data race检测:对RAZZER的2个VFS层漏洞进行测试,KRACE成功检测到。
8.结论与未来工作
扩展:
- a. 检测其他内核组件的
data race - b. 检测其他类型的并发漏洞
- c. fuzz分布式文件系统(不只有线程交错,还有网络事件排序,覆盖更难度量)
文档信息
- 本文作者:bsauce
- 本文链接:https://bsauce.github.io/2020/10/30/Krace/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)