【kernel exploit】CVE-2021-41073 内核类型混淆漏洞利用分析
影响版本:Linux 5.10~5.14.6 v5.14.7 已修补。
测试版本:Linux-5.14.6 exploit及测试环境下载地址—https://github.com/bsauce/kernel-exploit-factory
编译选项:CONFIG_FUSE_FS=y CONFIG_IO_URING=y
CONFIG_BINFMT_MISC=y (否则启动时报错) CONFIG_USER_NS=y (需调用 unshare(),才能使用FUSE3)
不要开启 CONFIG_BPF_JIT_ALWAYS_ON —— 否则interpreter 解释器就不会被编译到内核中,不能用本文劫持eBPF指令的方法提权。
不要开启 CONFIG_MEMCG / CONFIG_MEMCG_SWAP / CONFIG_MEMCG_KMEM —— 因为 seq_operations 对象分配时的 flag 是 GFP_KERNEL_ACCOUNT,会被隔离导致不能成功泄露内核基址,见 this(从5.14版本开始,内核会把分配时带GFP_KERNEL_ACCOUNT flag 的对象放入专属的 kmalloc-cg-* cache中,这样就将漏洞对象和msg_msg对象隔离开了,详见 commit-494c)。
在编译时将.config中的CONFIG_E1000和CONFIG_E1000E,变更为=y。参考
$ wget https://mirrors.tuna.tsinghua.edu.cn/kernel/v5.x/linux-5.14.6.tar.xz
$ tar -xvf linux-5.14.6.tar.xz
# KASAN: 设置 make menuconfig 设置"Kernel hacking" ->"Memory Debugging" -> "KASan: runtime memory debugger"。
$ make -j32
$ make all
$ make modules
# 编译出的bzImage目录:/arch/x86/boot/bzImage。
漏洞描述:fs/io_uring.c中的loop_rw_iter()函数存在 type confusion漏洞,io_kiocb->rw.addr 既充当内核地址又充当用户地址,但是在loop_rw_iter()函数中递增时没有作区分,导致在读文件时错误将内核地址递增,最后错误释放了相邻 kmalloc-32 堆块。
多数文件实现了文件操作函数 read_iter(),如果没有实现(例如 /proc/<pid>/maps 这种 procfs 文件),就手动调用 loop_rw_iter() 来迭代读写文件。req->rw.addr指针每次递增 read/write size,通常 req->rw.addr 指针指向用户空间,但是用户可以使用 IORING_OP_PROVIDE_BUFFERS 功能来预选一个buffer进行I/O操作。这样的话,req->rw.addr 可以指向内核buffer(io_buffer 结构),当读写完成后会调用 io_put_kbuf() 来释放该buffer。该漏洞可以将位于可控偏移处的相邻buffer释放掉。
本漏洞测试时,关闭了三个编译选项 CONFIG_SLAB_FREELIST_RANDOM / CONFIG_SLAB_FREELIST_HARDENED / CONFIG_BPF_JIT_ALWAYS_ON,但在实际环境中是默认开启的,所以利用的限制条件很严格,不实用。
补丁:patch
diff --git a/fs/io_uring.c b/fs/io_uring.c
index 16fb7436043c2..66a7414c37568 100644
--- a/fs/io_uring.c
+++ b/fs/io_uring.c
@@ -3263,12 +3263,15 @@ static ssize_t loop_rw_iter(int rw, struct io_kiocb *req, struct iov_iter *iter)
ret = nr;
break;
}
+ if (!iov_iter_is_bvec(iter)) {
+ iov_iter_advance(iter, nr);
+ } else {
+ req->rw.len -= nr;
+ req->rw.addr += nr;
+ }
ret += nr;
if (nr != iovec.iov_len)
break;
- req->rw.len -= nr;
- req->rw.addr += nr;
- iov_iter_advance(iter, nr);
}
return ret;
保护机制:开启KASLR/SMEP/SMAP。未开启 CONFIG_SLAB_FREELIST_RANDOM / CONFIG_SLAB_FREELIST_HARDENED / CONFIG_BPF_JIT_ALWAYS_ON(默认是开启的)。
利用总结:漏洞这个 UAF原语可以用来构造通用堆泄露,和覆写原语;4次用到FUSE在暂停拷贝;注意,exploit同目录下必须有一个 lol.txt 文件,因为在利用 setxattr() + getxattr() 泄露地址时,必须有实体文件和key进行绑定,否则不能获取到对应的key。
- (1)设置affinity,使应用程序线程和
io_uring中的io_wrk线程位于同一CPU核(使得io_buffer可以和目标object 相邻); - (2)喷射1000个
io_buffer结构来耗尽 kmalloc-32,使得接下来分配的 kmalloc-32 相邻; - (3)触发1:利用通用堆泄露原语来泄露 io_tctx_node 结构中的
io_tctx_node->task指针,指向属于我们的进程的task_struct结构;setxattr() + FUSE阻塞,会在(2)中最后一个io_buffer后面分配一个 kvalue(释放lock1);- 触发漏洞,利用
(2)最后1个io_buffer来释放偏移0x20处的 kvalue(触发漏洞的线程函数do_io_uring()获得 lock1,触发漏洞后释放 lock1); - (
do_io_uring2()函数线程获得 lock1)发送一个无关紧要的io_uring_prep_provide_buffers请求,目的是分配一个 io_tctx_node 结构来占据刚才释放的 kvalue 空间,继续等待 lock4; setxattr() + FUSE阻塞 3s 后恢复,拷贝最后一字节,将 io_tctx_node 结构当做kvalue注册进去了,接着释放 kvalue;getxattr()立刻将刚才注册进去的 kvalue 读取出来(泄露 io_tctx_node )。
- (4)触发2:利用通用堆泄露原语来泄露 seq_operations 结构中的
seq_operations->next指针,绕过KASLR;- 和
(3)类似的步骤。 - 不同点是,触发漏洞时利用倒数第2个
io_buffer来释放偏移0x40处的 kvalue;通过open("/proc/cmdline", O_RDONLY)来分配 seq_operations 结构来占据刚才释放的 kvalue 空间;用 lock2 来控制。
- 和
- (5)重新喷射1000个
io_buffer结构,占据 kmalloc-32; - (6)利用
setxattr() & getxattr()来伪造一个 fakebpf_prog结构;- 解锁 lock3,先分配一个 kvalue (稍后用于泄露堆地址);
pthread_mutex_lock()获取锁的顺序是先到先得,参见(mutex lock 唤醒顺序); - 3个
setxattr_thread_routine()子线程依次获得 lock3,利用setxattr() & getxattr()分配3个连续的key,以布置伪造的 fakebpf_prog结构(伪造bpf_prog->bpf_func & bpf_prog->insnsi,函数指针和eBPF指令,bpf_prog->bpf_func函数指针所在结构的偏移是 0x30,bpf_prog->insnsi指令所在结构的偏移是0x48); - 最后由
do_io_uring2()函数线程获得lock3,泄露堆地址;
- 解锁 lock3,先分配一个 kvalue (稍后用于泄露堆地址);
- (7)触发3:利用通用堆泄露原语来泄露某个 io_buffer 中的
io_buffer->list->prev指针,这样就泄露了堆中可控部分的地址,就能泄露 fakebpf_prog的地址;- 和
(3)类似的步骤; - 不同点是,通过
io_uring_prep_provide_buffers来分配2个io_buffer结构来占据刚才释放的 kvalue 空间;用 lock3 来控制; - 注意,泄露出来的堆地址,加上 0x30 就是 fake
bpf_prog结构的首地址,详细布局如下图所示。
- 和
- (8)提供 5 个buffer给
io_uring,对应要喷射5个io_buffer; - (9)触发4:伪造
sk_filter->prog,劫持控制流。- 分配 sk_filter 对象(调用
attach_bpf_prog(),将已加载的 eBPF 程序attach 到 socket,就会分配此对象); - 触发漏洞,释放 sk_filter 对象;
setxattr() + FUSE阻塞,kvalue占据sk_filter,向sk_filter拷贝伪造的数据(伪造最后8字节sk_filter->prog),3s后解除阻塞,释放kvalue;getxattr()立刻申请得到 kvalue (原先的sk_filter),伪造sk_filter->prog指向伪造的pf_prog(getxattr()调用copy_to_user()拷贝的目标地址会立刻暂停,长久驻留在内存中);- 释放 lock4,
(3)中的do_io_uring2()获得 lock4,调用run_bpf_prog()往绑定好BPF的socket 写入字符串,触发执行fake eBPF程序,劫持控制流。泄露的task_struct用于获取我们的进程的cred结构指针,并篡改 uid/euid。
- 分配 sk_filter 对象(调用
(7~9)堆布局如下所示: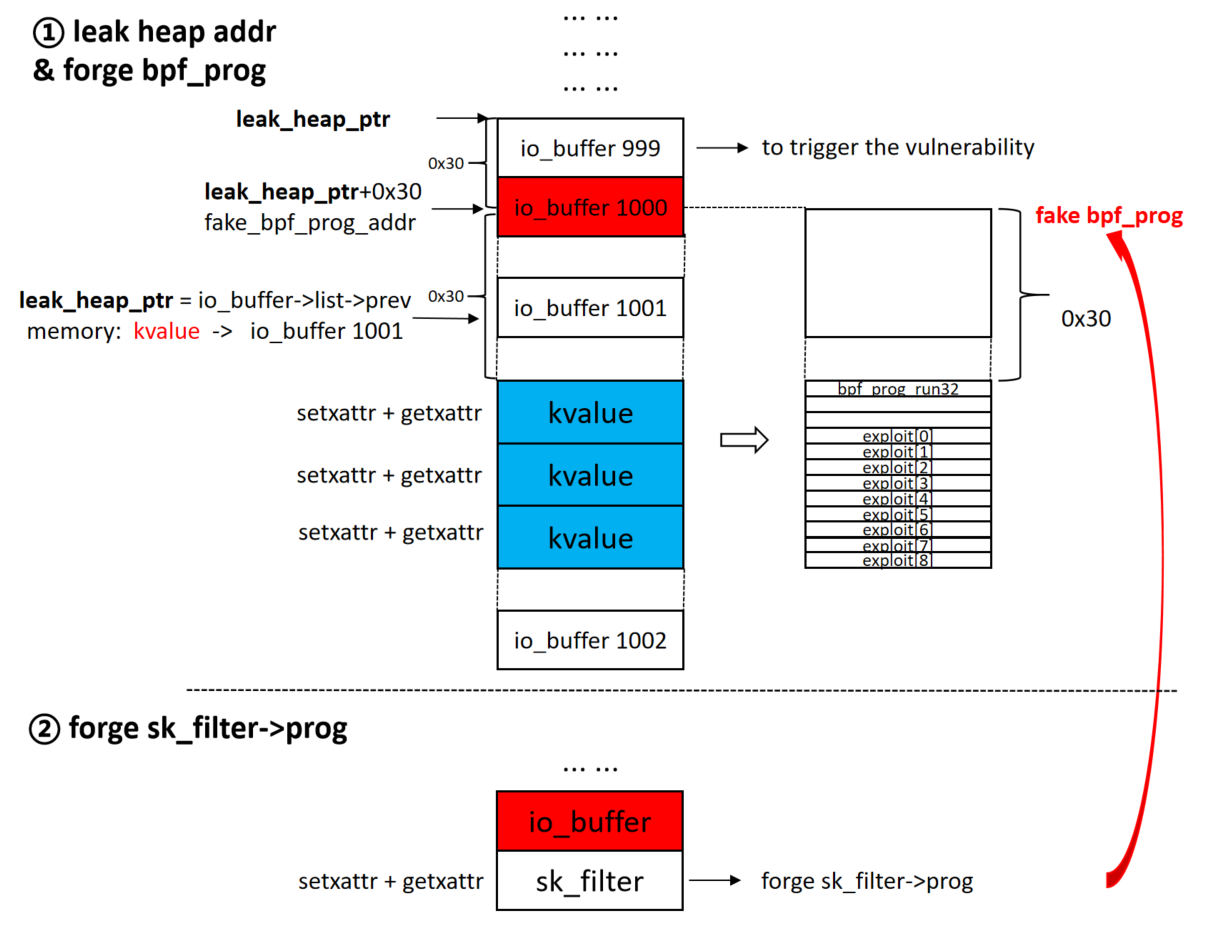
可学习的点:
ftrace 调试中的
trace event的使用,可以追踪内存分配与释放事件;可泄露
task_struct地址的结构——io_tctx_node;(新线程中发送io_uring请求时会分配该对象,局限性很大)可劫持控制流的结构——sk_filter;(当已加载的 eBPF 程序attach 到 socket时,会分配此对象,但必须关闭
CONFIG_BPF_JIT_ALWAYS_ON编译选项)setsockopt(socks[0], SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(int));
新的信息泄露方法:前提是要有这种释放原语(由于漏洞对象位于kmalloc-32,如果开启了
CONFIG_SLAB_FREELIST_RANDOM本方法也不适用,对稀有一点的、大一点的漏洞对象可能可以利用)。- 先
setxattr() + FUSE阻塞; - 释放
setxattr()中 kvalue 占据的堆块; - 用目标object(含可以泄露信息的对象)来占据 kvalue;
- 解除
setxattr() + FUSE阻塞,将目标object的内容当做kvalue注册进去了; - 调用
getxattr()将目标object泄露出来。
- 先
1. io_uring 介绍
简介:io_uring 是 Linux kernel 5.1 版本引入的高性能异步I/O框架。io_uring 支持存储文件和网络文件(network sockets),也支持更多的异步系统调用(accept/openat/stat/…),而非仅限于 read/write 系统调用。可以用于高性能应用程序,例如 server/backend 相关的需要大量I/O操作的应用程序。io_uring 所有功能选项位于 io_issue_sqe() 函数。
1-1 为什么使用 io_uring
动机:提高效率。
- 支持完全异步,这意味着应用程序在等待内核完成系统调用时不需要等待,可以先发出请求,然后干别的事儿,之后获得结果,减少了阻塞带来的时间开销。
- 一次可以发出大量系统调用请求。如果一个任务需要执行大量系统调用,现在可以降为1,甚至降为0(reference)。这样就减少了上下文切换带来的性能开销。
- 在
io_uring中,用户与内核之间的交互是通过共享缓冲区来进行的,这样降低了用户与内核之间数据拷贝带来的开销。
1-2 如何使用 io_uring
liburing库:参见 liburing,提供了简单的高层API,避免了直接使用更底层的系统调用(底层io_uring中主要是三个系统调用io_uring_setup() / io_uring_enter() / io_uring_register())。详细编程示例可参考 Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测。
1-3 io_uring 工作原理
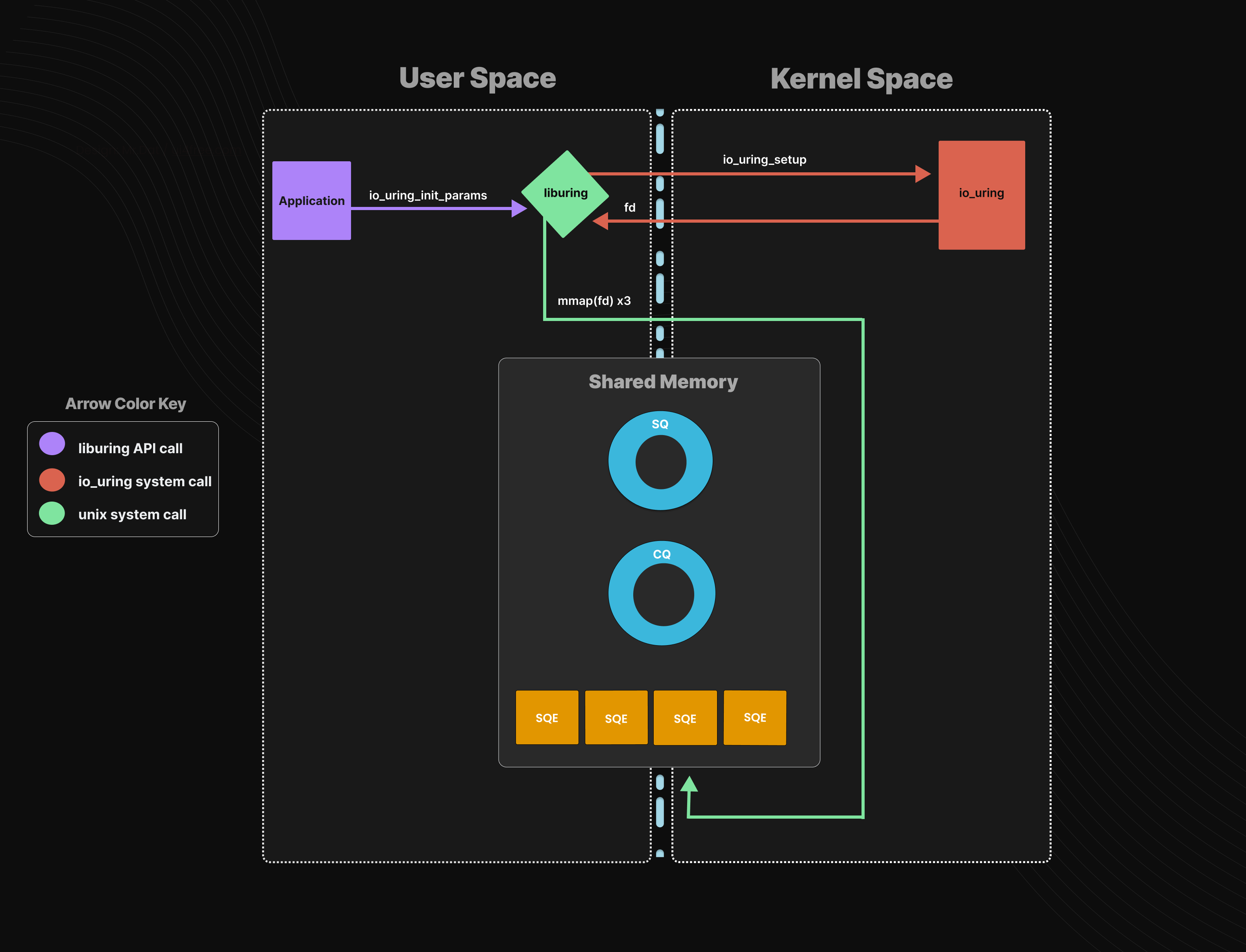
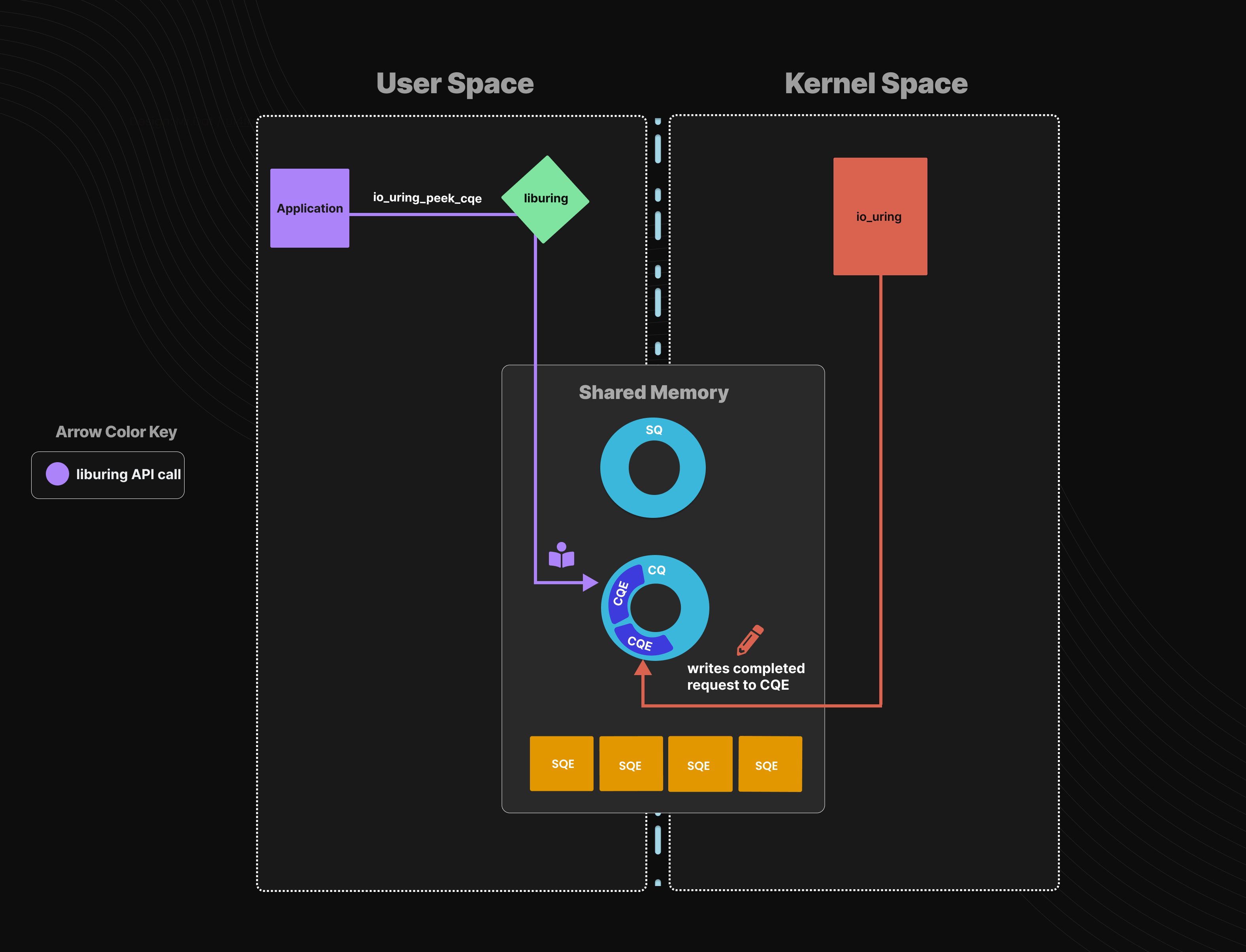
共享缓冲区:io_uring 的主要部分是内核和用户共享的 ring buffers ,首先调用 io_uring_setup() 来初始化一个 io_uring 实例,内核会返回一个文件描述符,并将 io_uring 支持的功能、以及各个数据结构在 fd 中的偏移量存入 params。用户根据偏移量将 fd 映射到内存 (mmap) 后即可获得一块内核用户共享的内存区域。这块内存区域中,有 io_uring 的上下文信息:
- 提交队列信息 (
SQ_RING) ,是一段ring buffer; - 完成队列信息 (
CQ_RING),是一段ring buffer; - 存放提交队列元素的区域 (SQE数组),需指定size。
(1)初始化 io_uring 的过程:
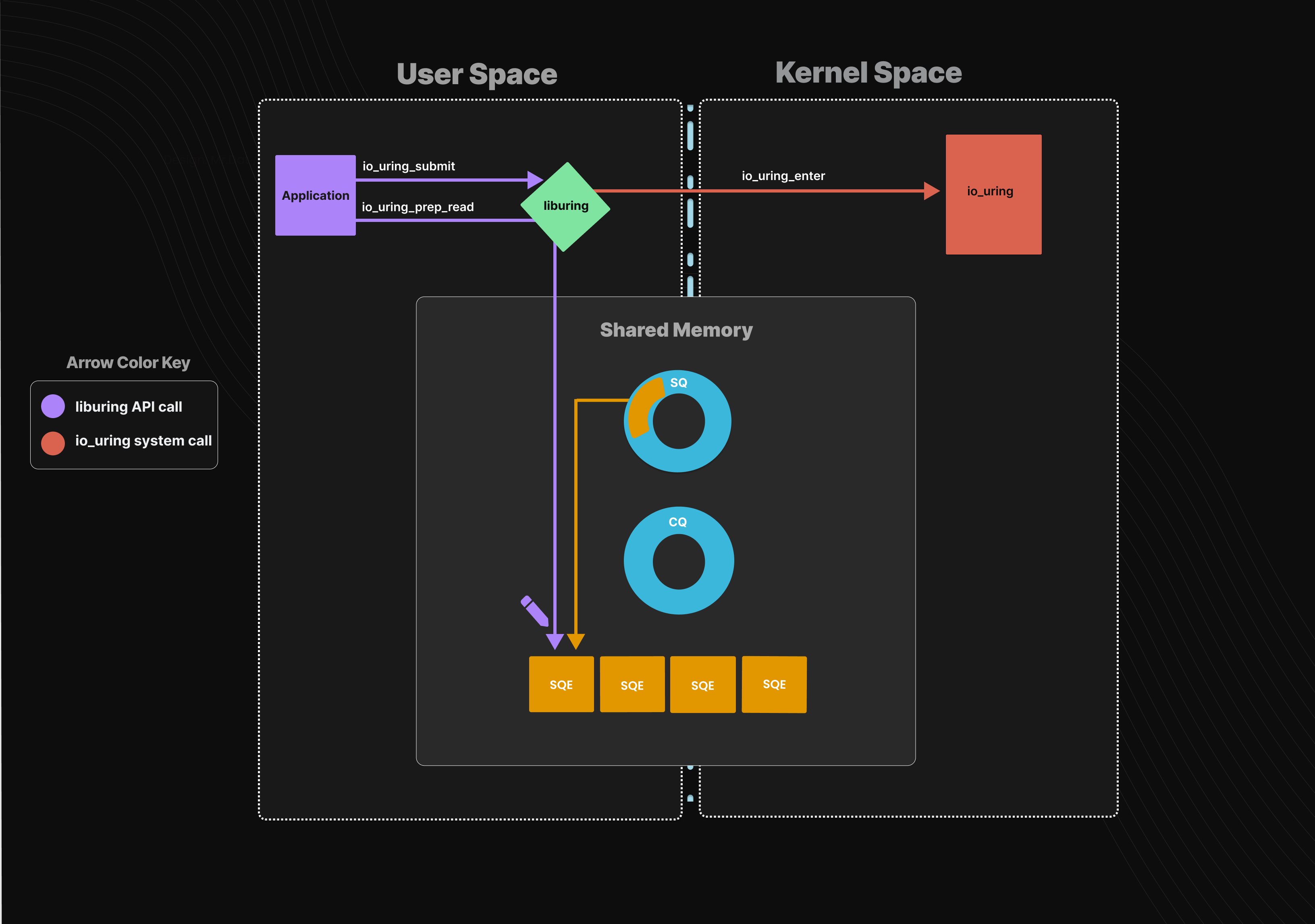
(2)提交请求的过程:每次发起请求时,填充SQE,并放入SQ。SQE描述了将要执行的系统调用操作,用户调用 io_uring_enter() 来告诉内核SQ上有任务了。如果使用了 IORING_SETUP_SQPOLL 特性,就会创建一个内核线程来轮询SQ任务,不需要调用io_uring_enter()来通知内核了。
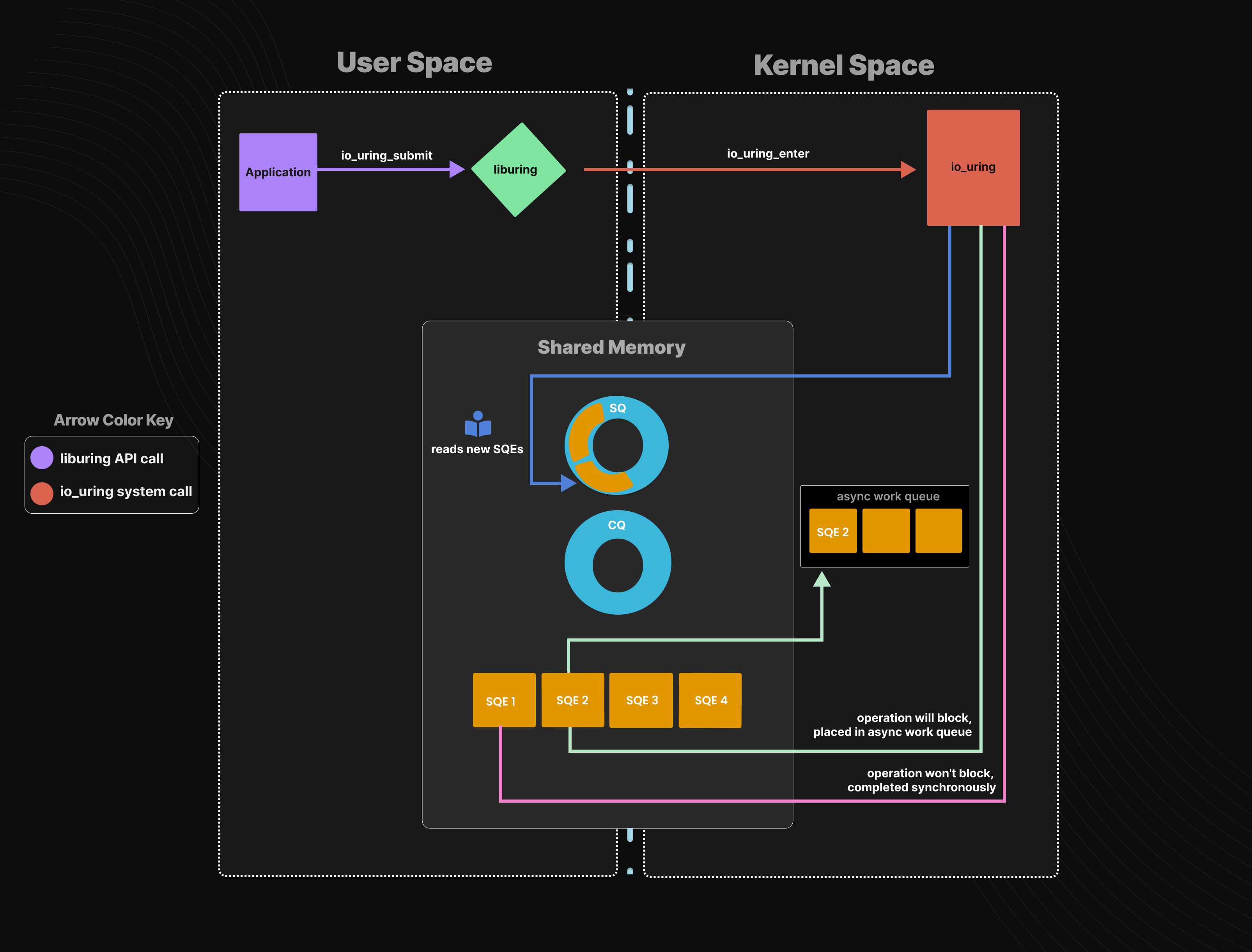
(3)判断是否异步执行操作的过程:完成每个SQE后,内核首先确定是否要异步执行操作。如果该操作不需要阻塞就能完成,就会在 calling thread 的上下文中同步完成;否则,它会被放入内核异步工作队列(async work queue),由 io_wrk 线程异步完成。两种情况下,calling thread 都不会阻塞,区别就是该操作会被 calling thread 立刻完成,还是被 io_wrk 线程稍后完成。
(4)完成操作:当操作完成,会将一个CQE(completion queue entry)放入CQ,应用程序可以轮询检查CQ是否有完成的CQE,以获知相应操作是否已经完成。SQE 可以以任何顺序完成,也可以link在一起以特定顺序完成。
2. 漏洞分析
动机:为什么要找 io_uring 的漏洞呢?作者最开始是在研究eBPF漏洞(参见Kernel Pwning with eBPF: a Love Story),而eBPF和 io_uring 都改变了用户与内核交互的方式。io_uring 是比较新的功能,而新的代码意味着有新的漏洞;由于 io_uring 内在并没有被 SELinux 用沙箱保护,所以在Android设备上提权较容易。总结下原因如下:
io_uring是Linux内核的一个新的子系统;- 它引入了很多新的交互方式,使非特权用户能和内核进行交互;
- 代码更新很快;
- 已经发现过可利用的漏洞;
io_uring中的漏洞可以用于Android提权。
2-1 新特性IORING_OP_PROVIDE_BUFFERS
新特性介绍:io_uring 引入了一个新的特性,叫做 IORING_OP_PROVIDE_BUFFERS,用户程序可以注册一个buffer pool,供内核执行操作时使用(通过 IOSQE_BUFFER_SELECT 来指定使用某个buffer) 。
由于 io_uring 异步的本质,为某个操作选择 buffer 是很复杂的,因为操作会在有限时间内完成,应用程序需记录哪些请求在使用哪些buffer。这个新的特性使得buffer选择变得自动化,减少了应用程序的负担。
提供 buffer pool 时,通过 buf_group (group id) 和 bid (buffer id)对buffer进行分组。注册完 buffer pool 后,当提交请求时,应用程序可以通过 IOSQE_BUFFER_SELECT flag 和 group ID 来指定使用某个buffer;操作完成后,通过CQE 将所用 buffer 的 bid 传回来(参见https://lwn.net/Articles/813311/)。
io_buffer结构:作者受到 CVE-2021-3491 的启发,来审计该功能的源码,发现一个漏洞。当注册一组 buffer 后,io_uring 内核组件为每个buffer分配了一个 io_buffer 结构,内核将给定 buf_group 的所有 io_buffer 结构保存在一个链表中。
struct io_buffer {
struct list_head list;
__u64 addr;
__u32 len;
__u16 bid;
};
io_kiocb->rw.addr:每个请求都对应一个 io_kiocb 结构,用于保存完成操作时需要用到的信息。其中包含一个域成员 rw,也即 io_rw 结构,保存了发起读写请求时的信息。
struct io_rw {
/* NOTE: kiocb has the file as the first member, so don't do it here */
struct kiocb kiocb;
u64 addr; // 读写时的目标地址, 用作内核地址时指向 io_buffer 对象
u64 len;
};
指定buffer:如果在发起请求时带有 IOSQE_BUFFER_SELECT flag,就会在读写之前调用 io_rw_buffer_select() 函数(调用序列 io_import_iovec() -> io_rw_buffer_select())。
[1]——req就是发起请求时指向io_kiocb结构的指针,[1]处很奇怪,所选buffer对应的io_buffer结构指针居然保存在req→rw.addr中,req→rw.addr本应该保存用户层的读写目标地址,在这里居然被填为一个内核地址。[2]—— 如果使用IOSQE_BUFFER_SELECTflag 发起请求,就会在内核中设置req->flags & REQ_F_BUFFER_SELECTflag,带有这个flag的请求会有不同的处理方式,后面不会使用req→rw.addr作为用户地址(读写时的目标地址),而是用作(io_buffer*) kbuf.addr(内核中的io_buffer对象地址)。
static void __user *io_rw_buffer_select(struct io_kiocb *req, size_t *len,
bool needs_lock)
{
struct io_buffer *kbuf;
u16 bgid;
kbuf = (struct io_buffer *) (unsigned long) req->rw.addr; // [1]
bgid = req->buf_index;
kbuf = io_buffer_select(req, len, bgid, kbuf, needs_lock);// io_buffer_select() —— 根据 bgid 找到对应的buffer组, 返回一个可用的 io_buffer (链表中最后一个 io_buffer)
if (IS_ERR(kbuf))
return kbuf;
req->rw.addr = (u64) (unsigned long) kbuf;
req->flags |= REQ_F_BUFFER_SELECTED; // [2]
return u64_to_user_ptr(kbuf->addr);
}
思考:使用同一域成员来存储用户指针和内核指针是很危险的,有没有地方忽略了 REQ_F_BUFFER_SELECT flag,从而把指针类型弄混了呢?
2-2 漏洞分析
漏洞分析:作者原本想找找在读写操作相关的代码中,有没有在设置 REQ_F_BUFFER_SELECT flag的情况下,把 req→rw.addr 地址用来读写的情况,很遗憾没有(这个错误直接写 io_buffer,有点低级)。但是在 loop_rw_iter() 中找到一处混淆。
- 对每个打开的文件描述符,内核都有一个关联的 file 结构(存储着 file_operations 结构指针
f_op,也即文件操作函数指针)。如果file没有实现read_iter/write_iter操作,就需要手动调用 loop_rw_iter() 来进行读写(例如/proc/self/maps等/proc文件,没有实现read_iter/write_iter操作)。 [1]—— loop_rw_iter() 前面进行了正确的检查,[1]处检查iter结构,如果设置了REQ_F_BUFFER_SELECTflag,则iter就不是bvec,否则将req→rw.addr用作读写的基址。[2]/[3]—— loop_rw_iter() 的功能是进行循环读写,在循环末尾[2]处,需将基址加上已读写的size,这样基址就指向接着读写的位置。如果带有REQ_F_BUFFER_SELECTflag,会在[3]处调用 iov_iter_advance() 再次递增基址。在[2]处没有像[1]那样进行检查,导致带REQ_F_BUFFER_SELECTflag时基址也被递增了。这就是类型混淆,[2]处代码把req→rw.addr当做了用户地址来递增(注意,带REQ_F_BUFFER_SELECTflag 时,req→rw.addr表示内核地址,指向io_buffer结构表示所选buffer,反之表示用户地址)。
/*
* For files that don't have ->read_iter() and ->write_iter(), handle them
* by looping over ->read() or ->write() manually.
*/
static ssize_t loop_rw_iter(int rw, struct io_kiocb *req, struct iov_iter *iter)
{
struct kiocb *kiocb = &req->rw.kiocb;
struct file *file = req->file;
ssize_t ret = 0;
/*
* Don't support polled IO through this interface, and we can't
* support non-blocking either. For the latter, this just causes
* the kiocb to be handled from an async context.
*/
if (kiocb->ki_flags & IOCB_HIPRI)
return -EOPNOTSUPP;
if (kiocb->ki_flags & IOCB_NOWAIT)
return -EAGAIN;
while (iov_iter_count(iter)) {
struct iovec iovec;
ssize_t nr;
if (!iov_iter_is_bvec(iter)) { // [1]
iovec = iov_iter_iovec(iter);
} else {
iovec.iov_base = u64_to_user_ptr(req->rw.addr); // 未设置 REQ_F_BUFFER_SELECT, 则将 req->rw.addr 用作读写地址
iovec.iov_len = req->rw.len;
}
if (rw == READ) {
nr = file->f_op->read(file, iovec.iov_base,
iovec.iov_len, io_kiocb_ppos(kiocb));
} else {
nr = file->f_op->write(file, iovec.iov_base,
iovec.iov_len, io_kiocb_ppos(kiocb));
}
if (nr < 0) {
if (!ret)
ret = nr;
break;
}
ret += nr;
if (nr != iovec.iov_len)
break;
req->rw.len -= nr;
req->rw.addr += nr; // [2] 漏洞点!!! 没有区分内核地址, 把io_buffer地址也递增了
iov_iter_advance(iter, nr); // [3]
}
return ret;
}
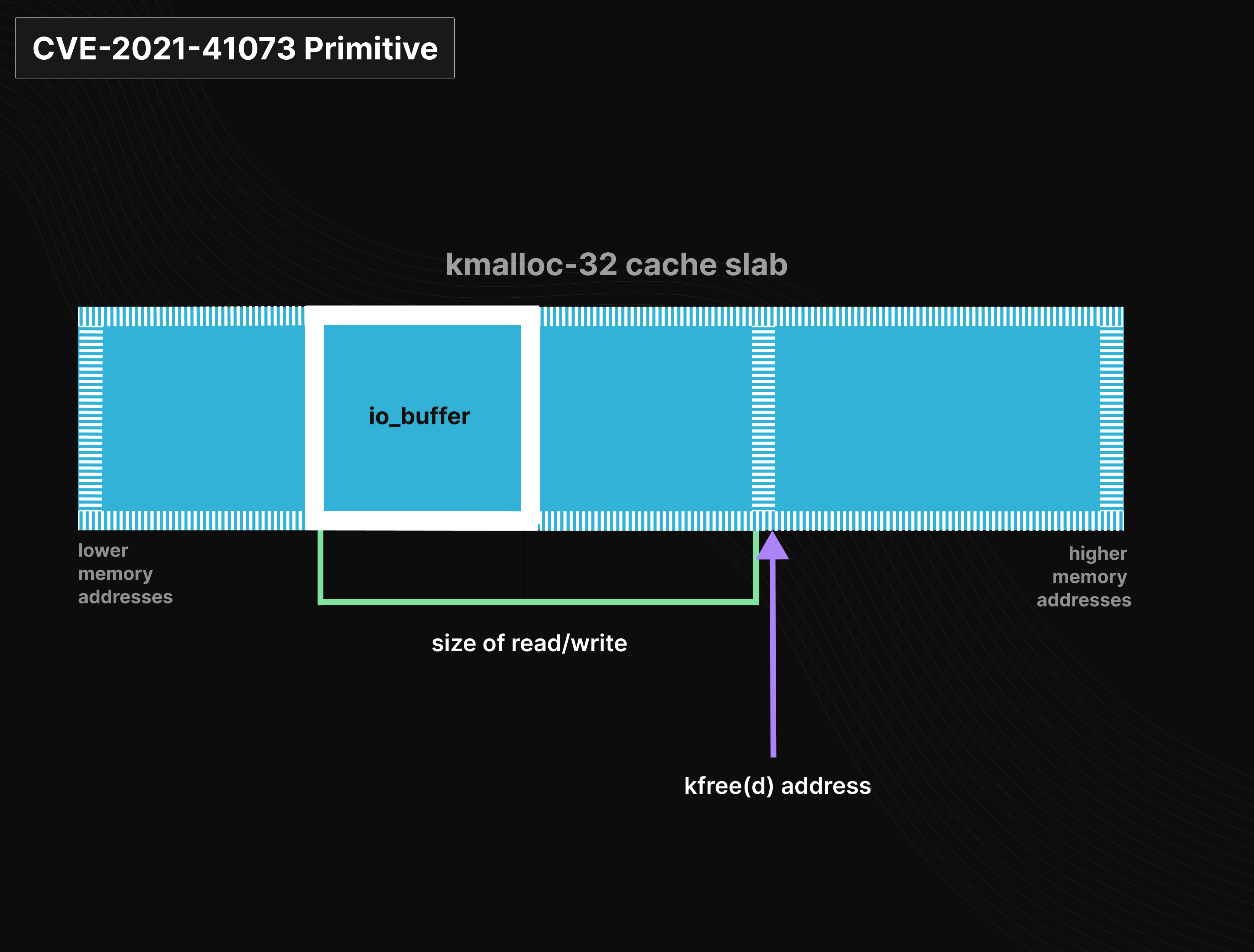
io_buffer释放:在执行操作时这里并没有什么影响,但是完成操作后,就会调用 io_put_rw_kbuf() 函数。若设置了该 REQ_F_BUFFER_SELECTED flag, 则调用 io_put_kbuf(),将 req→rw.addr 作为 kbuf 参数,并将该缓冲区(当做内核 io_buffer 对象)释放。由于该指针值已经递增了读写的size,所以释放的并非原先分配的buffer,实际释放的是 kfree(kbuf + user_controlled_value)。用户可以控制读写的size,也即 req→rw.addr 递增的值。
static inline unsigned int io_put_rw_kbuf(struct io_kiocb *req)
{
struct io_buffer *kbuf;
if (likely(!(req->flags & REQ_F_BUFFER_SELECTED))) // [1] 检查 REQ_F_BUFFER_SELECTED
return 0;
kbuf = (struct io_buffer *) (unsigned long) req->rw.addr;
return io_put_kbuf(req, kbuf); // [2] 若设置了该flag, 则调用 io_put_kbuf()
}
static unsigned int io_put_kbuf(struct io_kiocb *req, struct io_buffer *kbuf)
{
unsigned int cflags;
cflags = kbuf->bid << IORING_CQE_BUFFER_SHIFT;
cflags |= IORING_CQE_F_BUFFER;
req->flags &= ~REQ_F_BUFFER_SELECTED;
kfree(kbuf); // 释放 kbuf
return cflags;
}
由于 io_buffer 结构是32字节,所以可以释放 io_buffer 相邻可控偏移处的一个 kmalloc-32。漏洞原理如下图所示:
3. 漏洞利用
3-1 原语转化—从类型混淆到UAF
原语转化:exploit primitive是构成exp的基本块,一个exp需要用到多个原语一起才能实现代码执行和提权。有些原语更好,如任意读和任意写就是强原语。本例中我们获得的初始原语很弱,可以释放可控偏移处的内核buffer,但我们不知道buffer在哪、周围有什么,需要将该原语转化为有用的原语。
总目标:现在可以控制释放内核buffer,目标是转化为强的UAF原语。可以先分配一个对象,利用漏洞释放它,再分配一个对象来伪造数据。
问题:释放1个kmalloc-32,很难申请回来,可能是因为内核中太多对象用到了kmalloc-32,但作者发现不是这个问题。
3-2 Memory Grooming
SLUB内存管理:我们默认用的是SLUB分配器。SLUB保存多个内存cache(用kmem_cache 结构表示),每个cache保存类似size的对象。
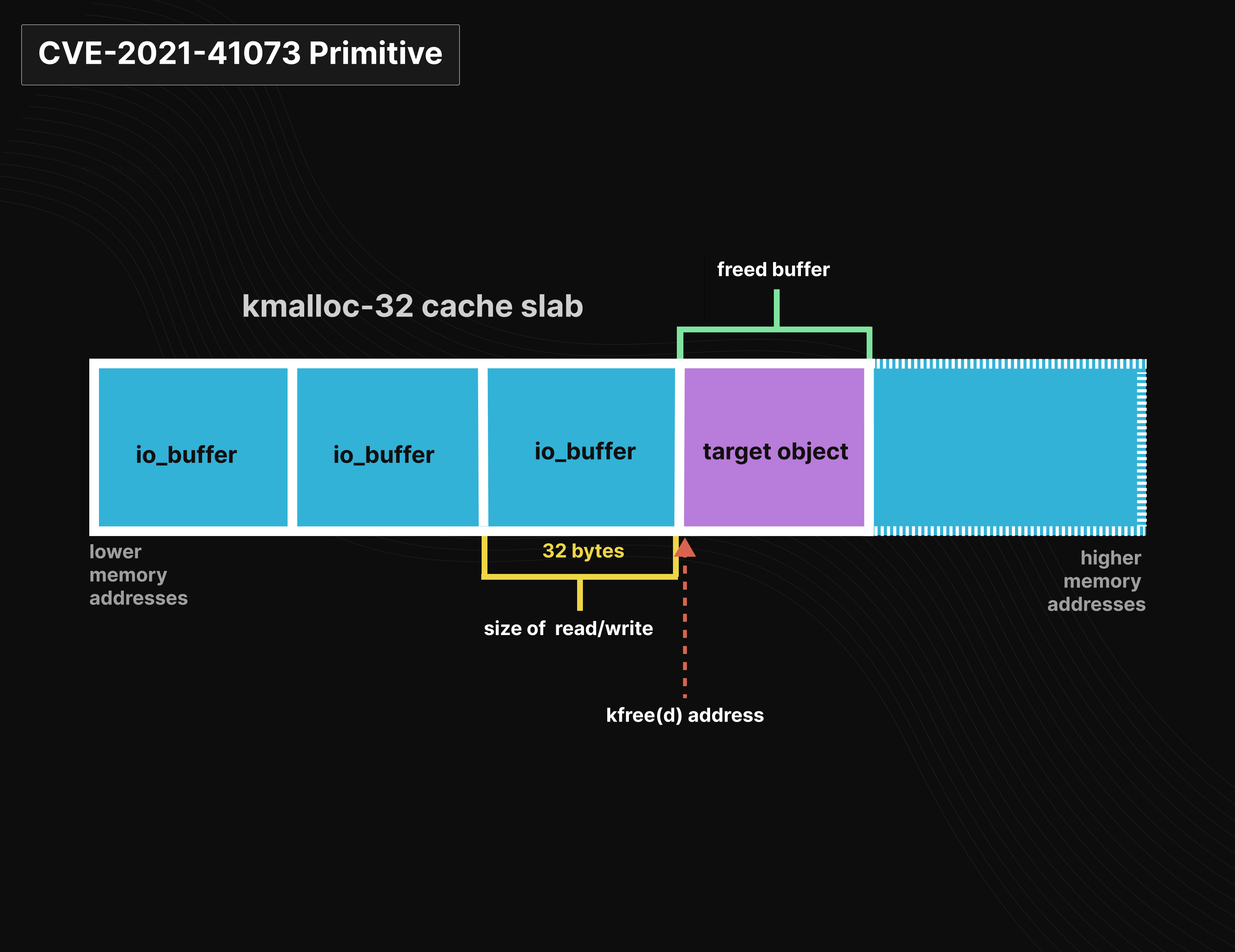
Memory Grooming:首先需要得到连续分配的buffer,将目标object放在 io_buffer 后面,并且偏移必须已知。
堆风水:先耗尽 cache 的freelist,保证下次分配的slab相邻。可以调用 liburing 中的 io_uring_prep_provide_buffers 来注册buffer,每注册一个buffer内核都会分配一个相应的
io_buffer。以下代码可以触发分配1000 个io_buffer结构,且会一直驻留在内存中,直到用于完成io_uring请求。io_uring_prep_provide_buffers(sqe, bufs1, 0x100, 1000, group_id1, 0);堆排布:需要使目标object和
io_buffer相邻。正好,buf_group中io_buffer的使用顺序是 LIFO,所以首先使用最近分配的io_buffer,这样目标object到io_buffer的偏移就已知了。
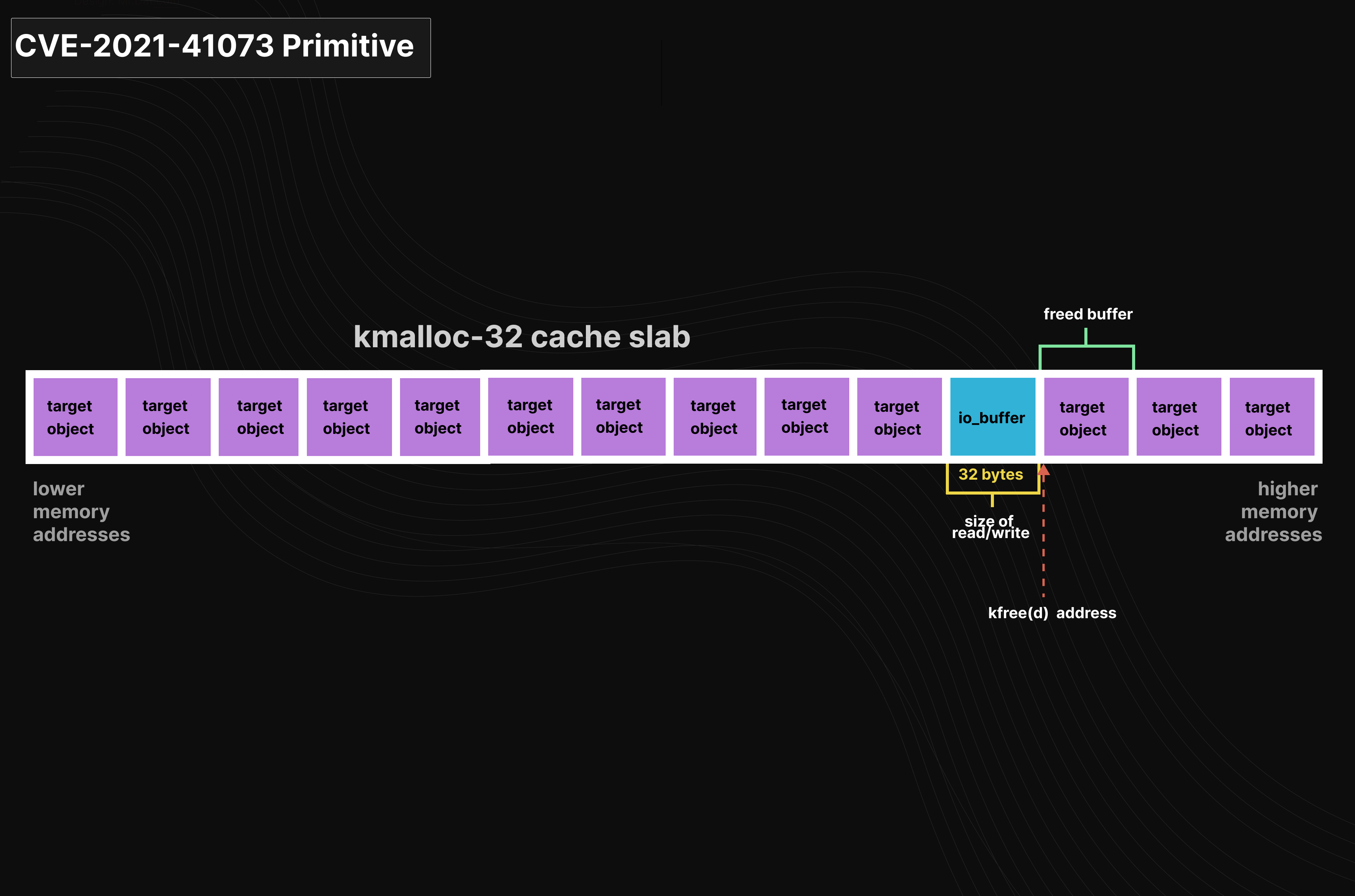
CONFIG_SLAB_FREELIST_RANDOM 防护:CONFIG_SLAB_FREELIST_RANDOM 编译选项在Ubuntu中是默认的 ,打乱了 freelist 中slab的顺序,导致分配的buffer不再连续。绕过方法是,首先在新分配的 slab page 上堆喷一个 io_buffer ,然后喷射目标 object,这样很有可能使目标object和 io_buffer 连续。随机化只针对 freelist 上的 buffer 顺序,但是list本身还是满足 LIFO的。堆布局如下所示:
3-3 Linux内核内存跟踪
目的:使用 ftrace 调试来追踪内存分配,弄清为什么不能申请到刚刚释放的 io_buffer 内存。
ftrace使用步骤:ftrace通常的使用步骤如下所示(参考linux性能工具–ftrace使用)。
$ echo 0 > tracing_on # Disable tracer
$ echo function > current_tracer # 设置tracer类型 - function
$ echo dev_attr_show > set_ftrace_filter # 设置tracer参数
$ echo 1 > tracing_on # Enable tracer
trace event使用:基于 ftrace 框架来实现,可以输出一些特定的事件,可通过命令 $ ls /sys/kernel/debug/tracing/events 来查看支持哪些事件,例如 kmem 中支持某些内存分配与释放函数的事件,每个事件中都包含一个 enable 文件,只需要往里面写入1,就可以trace这个事件。
/sys/kernel/debug/tracing/events/kmem # ls
enable mm_page_alloc
filter mm_page_alloc_extfrag
kfree mm_page_alloc_zone_locked
kmalloc mm_page_free
kmalloc_node mm_page_free_batched
kmem_cache_alloc mm_page_pcpu_drain
kmem_cache_alloc_node rss_stat
kmem_cache_free
/sys/kernel/debug/tracing/events/kmem/kmalloc # ls
enable filter format id trigger
/sys/kernel/debug/tracing/ # echo 1 > events/kmem/kmalloc/enable
/sys/kernel/debug/tracing/ # cat trace | head -15
/sys/kernel/debug/tracing/ # echo 1 > events/enable # 也可以 trace 所有事件
内存跟踪有很多种方式,本文作者采用 kmem event tracing subsystem (trace event)。设置很简单,将以下boot参数传给内核即可 —— trace_event=kmem:kmalloc,kmem:kmem_cache_alloc,kmem:kfree,kmem:kmalloc_node。
然后 $ cat /sys/kernel/debug/tracing/trace 即可追内存分配与释放,为避免虚拟内存地址混乱,可以加上 no_hash_pointers boot参数。
ftrace 输出:示例如下,第1/2/3行表示calling thread 的 task name / pid / CPU ID。第一行,你可以看到漏洞函数 io_put_kbuf() (被内联汇编到 kiocb_done() 函数中了)释放的buffer;第2行,是为了重新申请这块释放的buffer。

问题:该buffer是在 CPU 0 中被释放的,但是重新申请是在 CPU 1 中。这说明 io_uring 的读请求是异步的,发生在 iou_wrk 线程的上下文中,而堆申请发生在我们的进程中,导致不能申请到漏洞释放的对象。research 中提出的 sched_setaffinity 可以把线程放在指定的CPU core上运行,但是只对应用程序产生的线程有效,而我们需要控制的是 io_uring 内核组件创建的 io_wrk 线程。
解决办法:探索 io_uring 新的特性,看能不能控制 iou_wrk 线程的 affinity。
由于 io_uring 是面向性能的,作者很幸运找到一个特性可以使应用程序能控制 iou_wrk 线程的 affinity,就是几个月前引入的 IORING_REGISTER_IOWQ_AFF 。能够将exp进程的线程和 iou_wrk 线程放在同一CPU核上运行,调用 sched_setaffinity() 和 liburing库中的 io_uring_register_iowq_aff() 函数即可。这样就能重新分配得到漏洞释放的对象了。
3-4 通用堆喷 & 通用object覆写
通用堆喷:参见 Linux Kernel universal heap spray,采用 setxattr + userfault 进行堆喷,可以分配任何size的对象、完全控制对象的内容、使对象长久驻留在内核中。
setxattr() 可以控制分配对象的大小—— [1],并将用户数据拷贝进去——[2]。
static long
setxattr(struct user_namespace *mnt_userns, struct dentry *d,
const char __user *name, const void __user *value, size_t size,
int flags)
{
...
if (size) {
if (size > XATTR_SIZE_MAX)
return -E2BIG;
kvalue = kvmalloc(size, GFP_KERNEL); // [1]
if (!kvalue)
return -ENOMEM;
if (copy_from_user(kvalue, value, size)) { // [2]
error = -EFAULT;
goto out;
}
...
error = vfs_setxattr(mnt_userns, d, kname, kvalue, size, flags);
out:
kvfree(kvalue);
return error;
}
问题:现在内核提供了 Kconfig 选项来禁止非特权用户来使用 userfaultfd,多数Linux发行版都设置了 vm.unprivileged_userfaultfd。
解决:还可以使用 FUSE 。FUSE允许普通用户实现一个用户空间的文件系统,FUSE文件系统上的文件可以将读写转发到用户空间的应用程序,我们可以通过FUSE文件映射内存来阻止内核 copy/write。Userfaultfd需要映射两个页,在第2个页上设置用户页错误处理;而FUSE需要创建1个 anonymous 映射和1个file映射,使用mmap的addr参数来保证两个页相邻。
通用object覆写:触发漏洞释放对象后,setxattr() 分配size n 的对象,覆写前 n-8 字节然后阻塞。我们就能用这个覆写任意object原语来篡改某个 kmalloc-32。
3-5 通用堆泄露——新技术
目标:将通用堆喷原语转化为通用堆泄露原语,目标是泄露函数地址/cred结构/堆指针等。之前 setxattr() 重新分配得到了漏洞释放的对象,如果我们再把这个对象释放掉,会怎样呢?
步骤:
首先,利用
setxattr()堆喷拷贝前 n-8 字节,占据漏洞释放的对象;另一个线程再次触发漏洞释放
setxattr()buffer;接着触发分配对象来进行泄露,重新申请新对象(含有将被泄露的指针)来覆写
setxattr()用来存属性数据的 buffer;解除
setxattr()的阻塞,内核就会使用kvalue来设置文件属性,这样文件属性数据会被保存为二进制数据;调用
getxattr()来获取文件属性,注意,在设置文件属性之后,内核所使用的buffer已经被新对象的数据所覆写了。setxattr("lol.txt", "user.lol", xattr_buf, 32, 0); getxattr("lol.txt", "user.lol", leakbuf, 32);

3-6 目标object
介绍:以上都是介绍通用的利用方法,现在介绍下具体用到哪些对象。一开始,作者在 io_uring 中看到一些有意思的对象,有些指向 cred 和 task_struct 结构(Linux kernel Use-After-Free (CVE-2021-23134) 中用到了这类对象)。
搜索方法:作者采用很多方法来搜寻目标target,例如,使用内核内存tracing来测试分配了哪些 32 字节对象;写脚本利用pahole 来输出指定大小的结构;学习 CVE-2021-26708 中介绍的方法,配置某些编译选项,增加某些特性的同时,增加了可用的对象。
(1)可用于泄露的对象
io_tctx_node:新线程发送
io_uring请求时会分配该对象,一个进程可用分配多个该对象(如果多个子线程都调用io_uring)。可泄露的*task指针指向线程的task_struct,触发分配该对象的方法是,创建新的线程来调用io_uring系统调用。- 分配函数—— __io_uring_add_tctx_node()
struct io_tctx_node { struct list_head ctx_node; struct task_struct *task; struct io_ring_ctx *ctx; }; // __io_uring_add_tctx_node() struct io_tctx_node *node; node = kmalloc(sizeof(*node), GFP_KERNEL);io_buffer:本结构与漏洞有关,可以泄露
list链表指针(链接buf_group中其余的io_buffer),可以泄露堆地址,便于计算堆喷对象的地址。本对象还可以构造任意释放原语,篡改 list 成员然后unregister buffer 触发释放,不过本文的exp没有用到这个技巧。- 分配函数—— io_issue_sqe() -> io_provide_buffers() -> io_add_buffers()
struct io_buffer { struct list_head list; __u64 addr; __u32 len; __u16 bid; }; // io_add_buffers() struct io_buffer *buf; buf = kmalloc(sizeof(*buf), GFP_KERNEL);seq_operations:当某进程打开 seq_file 时就会分配本对象,本结构存储的函数指针用于对文件进行连续操作。通过打开
/proc/cmdline,就会分配本结构。可通过泄露 single_next() 函数来绕过 KASLR。- 分配函数 —— single_open()
struct seq_operations { void * (*start) (struct seq_file *m, loff_t *pos); void (*stop) (struct seq_file *m, void *v); void * (*next) (struct seq_file *m, void *v, loff_t *pos); int (*show) (struct seq_file *m, void *v); }; // single_open() struct seq_operations *op = kmalloc(sizeof(*op), GFP_KERNEL_ACCOUNT);
(2)可用于覆写的对象
sk_filter:当已加载的 eBPF 程序attach 到 socket时,会分配此对象。其中,prog 指针指向的 bpf_prog 结构表示 eBPF 程序,通过覆写该指针可以劫持控制流。问题是该指针位于 kmalloc-32 最后8字节,所以无法通过之前提到的 setxattr+FUSE 方法来覆写(只能覆写前 n-8 字节)。解决方法是,不阻塞 setxattr(),而是立刻调用 getxattr() 并阻塞, setxattr() 分配的buffer会在 getxattr() 中 reallocate(立刻申请回来,并覆写整个0x20 对象),这样在 copy_to_user 阻塞之前就覆写整个buffer。
分配函数:sock_setsockopt() -> sk_attach_bpf() -> __sk_attach_prog()
struct sk_filter {
refcount_t refcnt;
struct rcu_head rcu;
struct bpf_prog *prog;
};
struct bpf_prog {
u16 pages; /* Number of allocated pages */
u16 jited:1, /* Is our filter JIT'ed? */
jit_requested:1,/* archs need to JIT the prog */
gpl_compatible:1, /* Is filter GPL compatible? */
cb_access:1, /* Is control block accessed? */
dst_needed:1, /* Do we need dst entry? */
blinded:1, /* Was blinded */
is_func:1, /* program is a bpf function */
kprobe_override:1, /* Do we override a kprobe? */
has_callchain_buf:1, /* callchain buffer allocated? */
enforce_expected_attach_type:1, /* Enforce expected_attach_type checking at attach time */
call_get_stack:1; /* Do we call bpf_get_stack() or bpf_get_stackid() */
enum bpf_prog_type type; /* Type of BPF program */
enum bpf_attach_type expected_attach_type; /* For some prog types */
u32 len; /* Number of filter blocks */
u32 jited_len; /* Size of jited insns in bytes */
u8 tag[BPF_TAG_SIZE];
struct bpf_prog_stats __percpu *stats;
int __percpu *active;
unsigned int (*bpf_func)(const void *ctx, // <---------------
const struct bpf_insn *insn);
struct bpf_prog_aux *aux; /* Auxiliary fields */
struct sock_fprog_kern *orig_prog; /* Original BPF program */
/* Instructions for interpreter */
struct sock_filter insns[0];
struct bpf_insn insnsi[];
};
// __sk_attach_prog()
struct sk_filter *fp, *old_fp;
fp = kmalloc(sizeof(*fp), GFP_KERNEL);
3-7 整合
劫持控制流:覆写 sk_filter->prog 指针,bpf_prog 结构包含 bpf_func 函数指针,当关联的socket写入数据时会触发调用该函数,第2个调用指针参数指向 bpf_prog->insns (eBPF 解释器将用到的 BPF 指令)。
提权方法:现在,有多个提权选择。本文用的是第一种提权方法。
一是将
bpf_prog->bpf_func伪造成 ___bpf_prog_run() 函数地址,该函数解码并执行BPF指令(前提是,指令不是JIT编译的),然后伪造bpf_prog->insns中的eBPF指令来覆写cred,注意即便配置了 eBPF JIT 也还能用这种方法。问题是,如果 Kconfig设置了 CONFIG_BPF_JIT_ALWAYS_ON 选项, interpreter 解释器就不会被编译到内核中。二是找ROP链来提权,参考 CVE-2021-26708。gadget步骤如下:
- 需引用
bpf_prog->insns指针,这样就能引用我们放置的&task_struct→cred指针; - 往 uid 偏移处写0;
- 往 euid 偏移处写0;
- 返回。
可以通过获取 eBPF 程序返回值来进行泄露。分为两步(对应两段ROP),首先泄露
task->cred,然后覆写uid/euid。- 需引用
其实还有另一个选择,也即 JIT smuggling (之前Amy Burnett用它来进行浏览器利用),就是欺骗 JIT compiler 来创建 ROP gadget。eBPF JIT compiler 也可以用这个技巧。不需要泄露
single_next地址,二是泄露bpf_prog地址,使用原先JIT编译好的eBPF程序来夹带我们的ROP,由于BPF程序位于可执行页,所以可以跳转到该页上,执行我们夹带的gadget(注意,需计算好夹带的 ROP gadget 偏移,伪造bpf_prog->bpf_func跳转过去即可)。
测试截图:采用作者的测试环境,能够成功提权,但是我配置的环境总是失败。。。可能有两点原因,一是作者对内核的编译选项阉割了很多(比如说KVM都没有),二是启动脚本没有上防护机制 KASLR / SMEP / SMAP。
4. 缓解机制
io_uring 子系统引入了大量的内核代码,普通用户就可以访问。由于 io_uring 是系统调用,所以很难用沙箱来防护,我们可以通过过滤系统调用来防护,例如 seccomp 和 SELinux。
4-1 现有的Mitigation
CONFIG_SLAB_FREELIST_RANDOM:使得freelist上返回给用户的对象不再连续,但是 How a simple Linux kernel memory corruption bug can lead to complete system compromise 中提出,如果你可以控制释放顺序,你就能控制freelist,使随机化无效。因为只有分配新的 slab page 时才会有随机化。
CONFIG_BPF_JIT_ALWAYS_ON:这个配置选项移除了 eBPF interpreter,目的是减少可用 gadget 的数量。如果开启了 eBPF JIT,则必须设置该选项。
CONFIG_BPF_UNPRIV_DEFAULT_OFF:使非特权用户无法使用 eBPF,系统运行时可通过 sysctl 来修改。这样就能阻止通过 eBPF 来利用的exp。
CONFIG_SLAB_FREELIST_HARDENED:该选项是检查空闲对象的 metadate 是否正确,不能阻止本文的利用方式。但可能阻止一些其他原语,例如通过伪造空闲对象的 freelist metadata 指向某个目标地址,该选项会检查 freelist metadata 指向的地址是否位于有效的 slab page。
4-2 未来的思考
为 eBPF 程序实现 control flow integrity 会阻止本文提出的几种利用方法。当 eBPF 程序被 verified 并被 JIT 编译后,可将 entry point 添加到 valid targets,这样在程序执行之前进行检查,就能阻止本文提到的 ROP 方法、JIT smuggling 方法、interpreter 方法(若JIT开启)。
5. 补充
5-1 ftrace 查看函数调用栈
方法:设置 echo 1 > options/func_stack_trace 即可在 trace 结果中获取追踪函数的调用栈。
$ cd /sys/kernel/debug/tracing
$ echo 0 > tracing_on
$ echo function > current_tracer
$ echo schedule > set_ftrace_filter # function tracer 只跟踪某个函数
$ echo 1 > options/func_stack_trace
$ echo 1 > tracing_on
5-2 exploit编译与调试
作者的测试环境可参见 test_vm archive,exploit,内核版本是 v5.15-rc1。我的测试版本是 v5.16.4。
exp编译:需要安装 liburing 库。
# 作者:
$ gcc -o hello hello.c -Wall -std=gnu99 `pkg-config fuse --cflags --libs`
$ gcc -I include/ -o exploit exploit.c bpf.c -l:liburing.a -lpthread
# 我改编后,采用静态的libfuse3.a 库, 不需要安装 libfuse
$ gcc -no-pie -static exploit.c hellofuse.c bpf.c -I./libfuse libfuse3.a -l:liburing.a -o exploit -masm=intel -lpthread
vm启动脚本:
$ qemu-system-x86_64 \
-m 2G \
-smp 2 \
-kernel ./bzImage \
-append "console=ttyS0 root=/dev/sda earlyprintk=serial net.ifnames=0" \
-drive file=./stretch.img,format=raw \
-net user,host=10.0.2.10,hostfwd=tcp:127.0.0.1:10021-:22 \
-net nic,model=e1000 \
-nographic \
-pidfile vm.pid \
2>&1 | tee vm.log
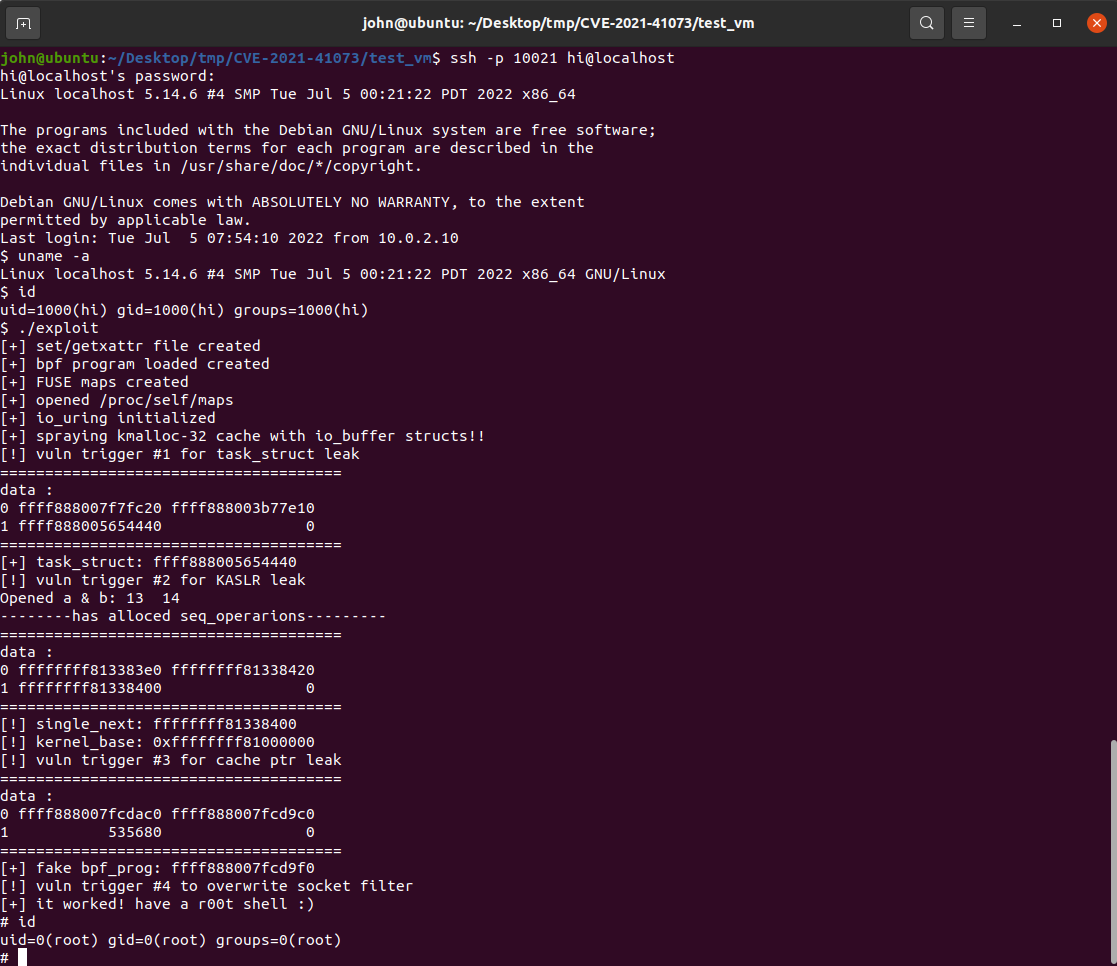
ssh连接与测试:这样就能以普通用户的身份登录进去,然后运行exploit,可能需要尝试3-4次才能利用成功。
$ ssh -p 10021 hi@localhost # password: lol
$ ./exploit
[+] set/getxattr file created
[+] bpf program loaded created
[+] FUSE maps created
[+] opened /proc/self/maps
[+] io_uring initialized
[+] spraying kmalloc-32 cache with io_buffer structs!!
[!] vuln trigger #1 for task_struct leak
[+] task_struct: ffff90740554c4c0
[!] vuln trigger #2 for KASLR leak
[!] single_next: ffffffffb2064520
[!] vuln trigger #3 for cache ptr leak
[+] fake bpf_prog: ffff9074056aacb0
[!] vuln trigger #4 to overwrite socket filter
[+] it worked! have a r00t shell :)
$ scp -P 10021 ./exploit hi@localhost:/home/hi # 传文件
$ scp -P 10021 hi@localhost:/home/hi/trace.txt ./ # 下载文件
# 安装 liburing 生成 liburing.a / liburing.so.2.2
$ make
$ sudo make install
# 安装 libfuse (我改编了exp, 本例中不需要安装 libfuse, 只需要采用离线的 libfuse3.a 库和相应头文件即可)
$ sudo apt-get install meson
$ mkdir build; cd build
$ meson ..
$ ninja
$ sudo python3 -m pip install pytest
$ sudo python3 -m pytest test/
$ sudo ninja install
ftrace调试:
# host端, 需具备root权限
cd /sys/kernel/debug/tracing
echo 1 > events/kmem/kmalloc/enable
echo 1 > events/kmem/kmalloc_node/enable
echo 1 > events/kmem/kfree/enable
cat trace > /home/hi/trace.txt
# ssh 连进去执行 exploit
# 下载 trace
scp -P 10021 hi@localhost:/home/hi/trace.txt ./ # 下载文件
5-3 知识点 — io_tctx_node 泄露 task_struct
分配:新线程中发出io_uring请求。参见 3-6 节。
5-4 知识点 — sk_filter 劫持控制流
分配:当已加载的 eBPF 程序attach 到 socket时,会分配此对象。参见 3-6 节。
5-5 liburing API 介绍
io_uring_queue_init_params():Initializes
io_uringfor use in your programs. In theio_uring_paramsstructure, you can only specifyflagswhich can be used to set various flags andsq_thread_cpuandsq_thread_idlefields, which are used to set the CPU affinity and submit queue idle time. Other fields of the structure are filled up by the kernel on return.int io_uring_queue_init_params(unsigned entries, struct io_uring *ring, struct io_uring_params *p)io_uring_get_sqe():gets the next available submission queue entry from the submission queue belonging to the ring param.
struct io_uring_sqe *io_uring_get_sqe(struct io_uring *ring)io_uring_prep_provide_buffers():为什么引入?若给每个操作都分配缓冲区,但有些操作在未来一段时间内无法执行到,对于需要等待许多操作的应用程序来说,内存使用量大大增加。本函数可以向 io_uring 提供多个buffer pool,当需要用到缓冲区时,io_uring 会从其中的一个 buffer pool 中选择一个buffer(允许在operation在ring中排队之后再分配缓冲区)。 接下来在队列中插入后续operation的时候就可以不提供buffer,而是使用一个特殊值
IOSQE_BUFFER_SELECT。队列中每个entry中新增的buf_group字段应设置为目标buffer group ID。当一个operation具备继续执行的条件时,内核将从指定buffer group中获取一个缓冲区来使用。- 为了使用这种机制,应用程序开始时,需要先在队列中插入若干个IO_ING_OP_PROVIDE_BUFFERS操作,从而告诉内核我这边提供了哪些I/O buffers。每个操作都提供了缓冲区的基本地址、缓冲区的计数、缓冲区的大小(一次operation中所有缓冲区都是一样大的)、base buffer ID和group ID。如果请求中包含了一个以上的缓冲区,buffer ID将针对每个buffer来递增。
- 接下来在队列中插入后续operation的时候就可以不提供buffer,而是使用一个特殊值IOSQE_BUFFER_SELECT。队列中每个entry中新增的buf_group字段应设置为目标buffer group ID。当一个operation具备继续执行的条件时,内核将从指定buffer group中获取一个缓冲区来使用。在选择时并不考虑缓冲区的大小,因此如果缓冲区太小的话operation将无法正常完成。被使用的buffer ID会在operation完成时跟completion status一起返回。
static inline void io_uring_prep_provide_buffers(struct io_uring_sqe *sqe, void *addr, int len, int nr, int bgid, int bid)io_uring_submit():提交请求,Submits the SQEs acquired via
io_uring_get_sqe()to the kernel. You can call this once after you have calledio_uring_get_sqe()multiple times to set up multiple I/O requests.int io_uring_submit(struct io_uring *ring)io_uring_prep_read():sets up the submission queue entry pointed to by
sqewith a read operation.void io_uring_prep_read(struct io_uring_sqe *sqe, int fd, void *buf, unsigned nbytes, off_t offset)io_uring_sqe_set_flags():This is an inline convenience function that sets the flags field of the SQE instance passed in.void io_uring_sqe_set_flags(struct io_uring_sqe *sqe, unsigned flags)io_uring_wait_cqe():Returns an I/O completion, waiting for it if necessary.int io_uring_wait_cqe(struct io_uring *ring, struct io_uring_cqe **cqe_ptr)io_uring_cqe_seen():Must be called after
io_uring_peek_cqe()orio_uring_wait_cqe()and after the cqe has been processed by the application.void io_uring_cqe_seen(struct io_uring *ring, struct io_uring_cqe *cqe)
参考
Put an io_uring on it: Exploiting the Linux Kernel
io_uring - new code, new bugs, and a new exploit technique
CVE-2021–20226 a reference counting bug which leads to local privilege escalation in io_uring —— 最开始介绍 io_uring 利用的文章,未公开exp
Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测
文档信息
- 本文作者:bsauce
- 本文链接:https://bsauce.github.io/2022/07/11/CVE-2021-41073/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)